
ADS построена на базе Apache Kafka и Apache NiFi и включает все необходимые компоненты (NiFi Registry, MiNiFi и т. д.). В этой статье я расскажу о том, как подойти к работе с NiFi с точки зрения потокового программирования и организовать взаимодействие с базами данных (включая все ключевые процессоры NiFi для выгрузки, загрузки и трансформации данных).
Материал будет полезен тем, кто только начинает знакомиться с NiFi и хочет лучше разобраться в концепциях потоковой (Flow-Based) обработки данных, а также в использовании универсального потока метаданных. Мы затронем и важные технические детали, чтобы вы могли без труда перенести теорию на реальную практику.
О продукте Arenadata Streaming
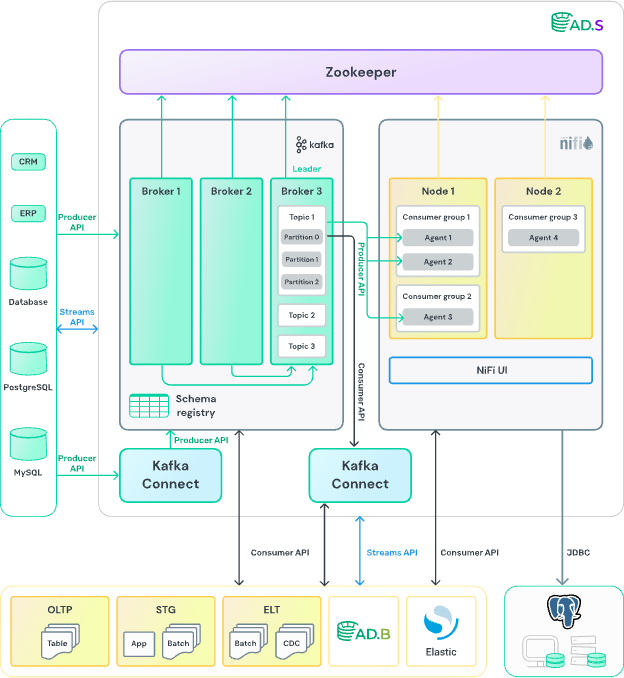
В состав ADS входит Kafka и его экосистема — Kafka Rest, Kafka Streams, Kafka Connect, Kafka SQL, Schema Registry, а также NiFi и его компоненты NiFi Registry и MiNiFi. Более подробно о продукте можно узнать по ссылке.
Типовые сценарии применения ADS включают использование её в качестве шины данных, единой точки обмена данными для микросервисов, системы ETL и CDC. Более подробно можно прочитать в разделе.
Стоит сказать несколько слов о NiFi. Это low-code масштабируемое средство для построения интеграционных процессов в режиме, близком к реальному времени. NiFi подходит для ETL-процессов, разработки интеграций, может выступать в качестве шины данных. Подробнее о NiFi можно прочитать в этом разделе.
ADS.NiFi и концепция потокового (Flow-Based) программирования
Apache NiFi (и продукт Arenadata Streaming NiFi — ADS.NiFi) опирается на подход под названием Flow-Based Programming (FBP). Суть в том, что у нас есть сеть процессоров, обменивающихся сообщениями (FlowFile в NiFi) по заранее определённым связям (очередям). Преимущества такого подхода:
- Простая визуальная модель
Мы видим на экране ориентированный граф, где вершины — это процессоры, а рёбра — очереди, по которым движутся данные. - Разделение процессов и данных
Каждый «чёрный ящик» не знает ничего о предыдущем или следующем шаге. У него есть только входные данные (FlowFile) и заданный алгоритм обработки. Это обеспечивает низкую связанность и повышает гибкость. - Упор на метаданные (атрибуты FlowFile)
Вся дополнительная информация (что, откуда, какой формат) прикладывается к самому FlowFile в виде атрибутов. NiFi-логика базируется на этих атрибутах.
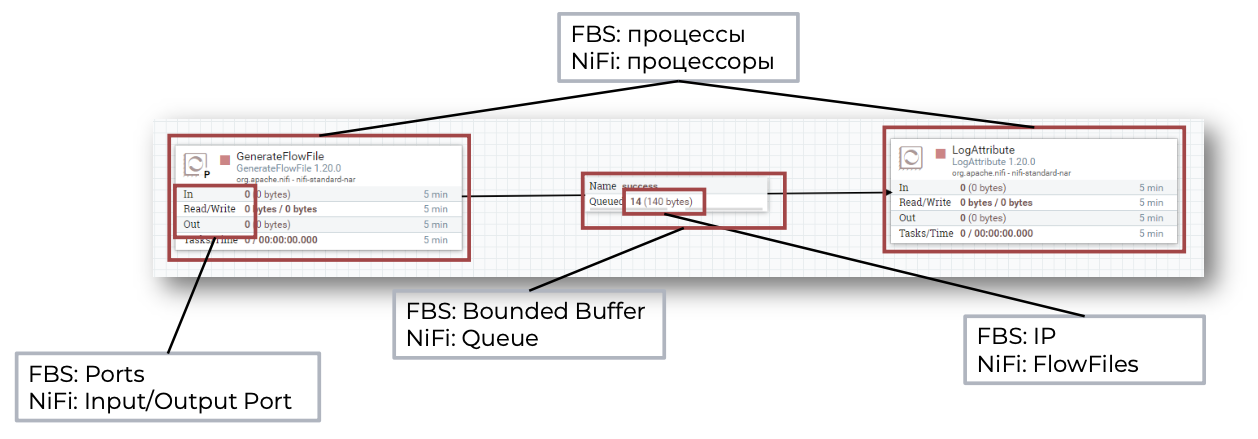
Что такое FlowFile
FlowFile — это основной объект обмена внутри NiFi. Он состоит из двух частей:
- Атрибуты (Attributes) — набор пар «ключ-значение», отражающих метаданные (например, имя файла, его размер, время создания, кастомные поля).
- Контент (Content) — произвольная последовательность байтов (например, текст, CSV, JSON, бинарные данные), которая лежит в репозитории на диске и подгружается NiFi «по требованию».
Чтобы данные начали обрабатываться, они должны попасть в очередь (Connection). Процессор, стоящий на входе этой очереди, забирает FlowFile и выполняет необходимую операцию. Затем FlowFile передаётся дальше, по следующему ребру графа, или уходит на выход.
Процессоры и очереди
Вместо традиционной парадигмы «функции, классы, методы» в NiFi вы работаете с процессорами (Processors). Каждый процессор выполняет узкоспециализированную операцию над FlowFile:
- чтение или запись данных во внешние системы;
- преобразование (трансформация, фильтрация, маршрутизация);
- работа с атрибутами, шифрование, валидация и многое другое.
Преимущества FBP (Flow-Based Programming) в NiFi
- Масштабирование и отказоустойчивость. При правильной архитектуре все процессы можно параллелить, а сбой на одном узле не останавливает обработку, если остальные в кластере продолжают работу.
- Визуальная разработка. Большую часть интеграций и ETL-процессов реально собрать «из коробки», буквально перетаскивая процессоры на canvas.
- Низкая связанность. Каждый процессор сосредоточен на своей задаче и использует только атрибуты входного FlowFile. Это упрощает отладку и масштабирование.
Так NiFi превращается в low-code платформу для интеграции и обработки данных в режиме, близком к реальному времени (streaming). Причём Arenadata Streaming NiFi (ADS.NiFi) добавляет к базовым возможностям Apache NiFi улучшения для корпоративного применения: консоль управления, интеграцию со службой безопасности и т. д.
Атрибуты FlowFile и работа с ними
В NiFi все операции строятся вокруг того, что FlowFile = Attributes + Content. Атрибуты (пары «ключ-значение») загружаются в оперативную память и могут дополняться процессорами в ходе обработки. Контент (набор байтов) при этом может вовсе отсутствовать либо храниться на диске, что предотвращает избыточную загрузку в память. Благодаря такой модели каждый процессор ничего не знает об остальных шагах — ему достаточно данных, содержащихся в текущем FlowFile, что формирует основу Flow-Based Programming в NiFi.
Почему атрибуты так важны
- Управление процессом: большинство процессоров маршрутизации (RouteOnAttribute, RouteOnContent и т. д.) принимают решения на основе значений атрибутов.
- Гибкие сценарии обработки: вы можете записывать в атрибут любую информацию, необходимую для дальнейших шагов (например, имя выходного файла, хеш контента, признак «ошибочной» записи и т. д.).
- Performance-заметка: атрибуты загружаются целиком в оперативную память, так что не стоит перегружать FlowFile десятками мегабайт в виде пар «ключ-значение». Храните там только нужное.
Основные (Core) атрибуты
NiFi автоматически создаёт несколько ключевых атрибутов для каждого FlowFile:
- filename — логическое имя файла (может использоваться при записи на диск);
- path — путь к файлу или директории (при записи на диск или FTP);
- uuid — уникальный идентификатор FlowFile, генерируемый NiFi;
- entryDate — дата создания FlowFile в NiFi в миллисекундах с 1 января 1970 года (UTC);
- lineageStartDate — дата создания самого «древнего предка» данного FlowFile (если в ходе обработки он был разделён, склеен и т. п.);
- fileSize — размер контента FlowFile в байтах.
Атрибуты uuid, entryDate, lineageStartDate и fileSize задаются системой и не могут быть изменены пользователем.
Обработка атрибутов: типовые процессоры
NiFi содержит целый набор специализированных процессоров, которые позволяют извлекать, создавать, редактировать атрибуты:
- EvaluateJsonPath, EvaluateXPath, EvaluateXQuery
используются, чтобы вытащить нужные фрагменты из JSON/XML и сохранить их как атрибуты. - ExtractText
извлекает данные из контента по регулярному выражению и записывает их в атрибуты. - HashAttribute, HashContent
создают хеши по указанным атрибутам или контенту (MD5, SHA и т. д.). - UpdateAttribute
универсальный процессор для изменения, добавления или удаления атрибутов. Поддерживает Expression Language.
Expression Language (EL)
Одним из самых мощных механизмов NiFi для работы с атрибутами является Expression Language (EL). С его помощью можно:
- собирать значения нескольких атрибутов в один;
- выполнять проверки (например, «начинается ли имя файла с…»);
- преобразовывать типы (int, float, date), выполнять математику;
- управлять маршрутизацией (true/false) и многим другим.
Синтаксис:
- Выражение в EL обрамляется фигурными скобками и начинается со знака $:’${attributeName}’
- Можно накладывать функции с двоеточием: ‘${filename:startWith(‘prefix’):not()}’ вернёт true, если filename не начинается с ‘prefix’.
Как NiFi ищет значения (при вычислении EL):
- Смотрит среди атрибутов текущего FlowFile.
- Ищет переменные в Process Group (если определены).
- Проверяет NiFi Variable Registry.
- Анализирует JVM-параметры.
- Смотрит системные переменные.
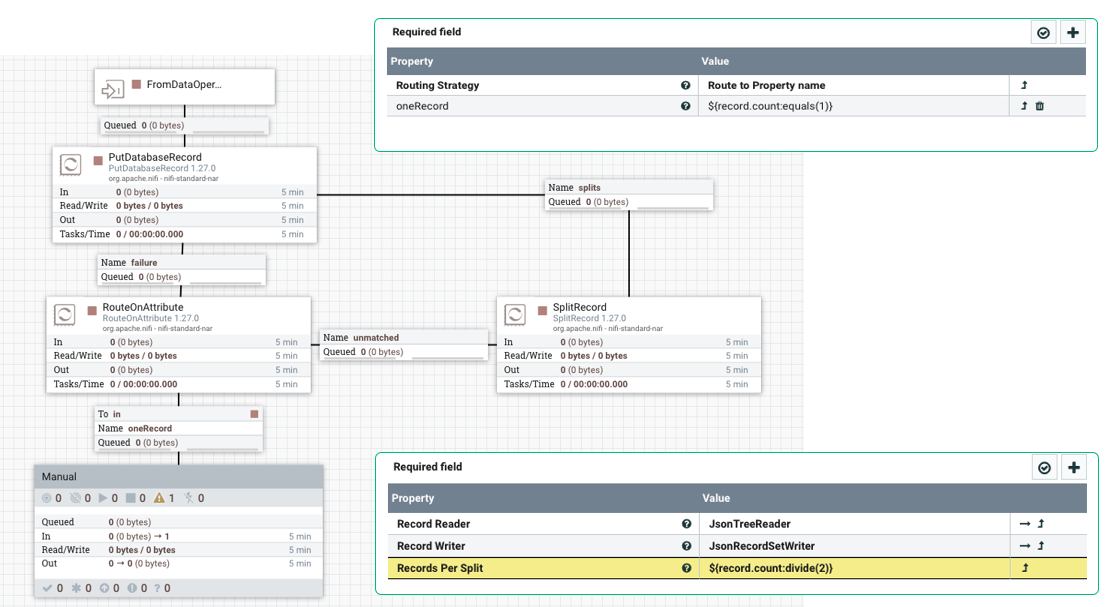
Пример: пусть у нас есть атрибут record.count, показывающий количество записей в файле.
- Чтобы проверить, что в файле ровно одна запись, пишем условие в маршрутизирующем процессоре: ‘${record.count:equals(1)}’
- Если хотим разделить набор записей пополам, берём ‘${record.count:divide(2)}’, и используем это значение для SplitRecord или UpdateAttribute.
Пример использования EL
- UpdateAttribute
- Property Name: file_category
- Value: ‘${filename:startsWith(‘report’):toString()}’ — Так, если filename начинается на report, атрибут file_category станет true, иначе — false.
- RouteOnAttribute
- В Relationship «true» отправляем все файлы, у которых file_category = true.
Таким образом, Expression Language даёт возможность динамически подставлять нужные значения атрибутов и принимать решения на лету.
Инициализация потока обработки
В ADS.NiFi поток обработки данных начинается с генерации начального FlowFile. Обычно для генерации стартового триггера применяется процессор GenerateFlowFile. Существует два варианта расписания запуска процессора: через равные промежутки времени либо по заданному расписанию Cron.
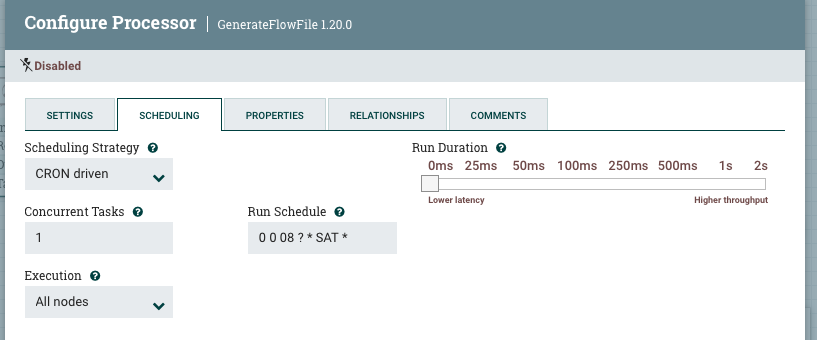
При запуске через равные интервалы времени возможен риск того, что источник не успеет отдать все данные либо поток не успеет доставить выгруженные данные до старта новой итерации. При запуске по расписанию всегда будет задача, которую не сможем покрыть одним выражением Cron. Казалось бы, применение одновременно двух вариантов поможет решить все задачи, но всегда возникнет необходимость расширить существующие расписания либо изменить их для определённых потоков. И потребуется вносить изменения в сам пайплайн.
Сделать универсальным старт потока обработки можно. Для этого в процессоре GenerateFlowFile я определяю интервал запуска раз в минуту и добавляю атрибут schedule, вычисляемый как текущее время с точностью до минуты. Также возможно определить любое требуемое расписание. Например, 15min — запуск раз в 15 минут, 1Sat — 1-я суббота месяца.
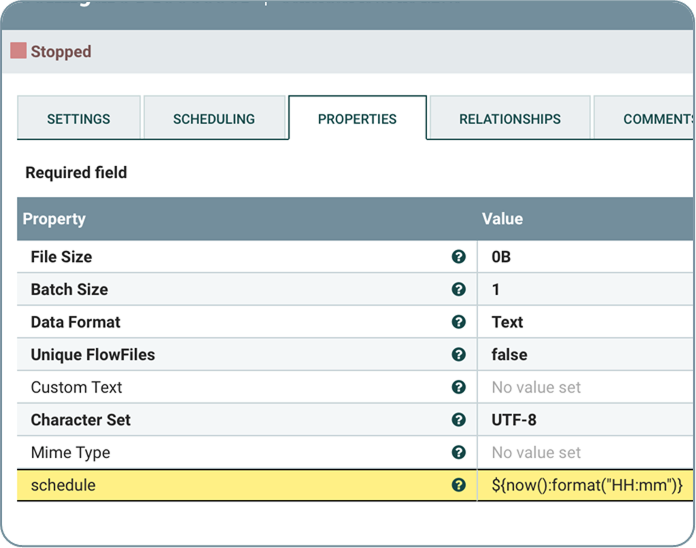
Зададим в базе данных таблицу с полями, содержащими идентификатор потока, текстовые названия исходных и целевых систем, схем и таблиц, а также расписание, которое представляет собой текстовое поле, содержащее все расписания запуска для этого потока. Расписания разделены точкой с запятой.
CREATE TABLE flow_metadata (
Id int IDENTITY(1,1) NOTNULL,
src_erp nvarchar(30) NOTNULL,
src_schema nvarchar(100) NOTNULL,
src_table nvarchar(MAX) NOTNULL,
tgt_erp nvarchar(30) NOTNULL,
tgt_schema nvarchar(50) NOTNULL
tgt_table nvarchar(MAX) NOTNULL,
column_list nvarchar(MAX) NULL,
avro_schema nvarchar(MAX),
last_start datetime NULL,
last_complete datetime NULL,
active bit DEFAULT 1 NOTNULL,
schedule nvarchar(250) DEFAULT '0' NOTNULL
);Ранее расписание я определил в атрибуте генерируемого FlowFile. Чтобы получить описание потока, нужно выполнить запрос к базе, например:
Select * from ${paramtable}
where active = 1 AND
'${schedule}' in (select value from string_split(schedule,';'))Получив метаданные, определяющие поток, я переношу их из контента в атрибуты и получаю готовый триггер для старта обработки данных. И если с потоком, где возможно инициировать выгрузку данных, всё довольно просто, то как быть с потоками, когда данные поступают от брокеров сообщений, например от Kafka? Ведь в этом случае триггер отсутствует, а FlowFile уже будет содержать полученные от брокера сообщений данные.
В этом случае следует учесть важное условие, а именно: все данные, получаемые от Kafka либо другого брокера, должны иметь идентификатор, по которому можно однозначно опередить структуру сообщения. Например, это может быть имя топика либо определённый заголовок в сообщении Kafka. В этом случае можно запросить метаданные после получения самих данных от брокера. К сожалению, процессор ExecuteSQLRecord перезапишет контент, поэтому в этом случае я применяю простой скрипт на Groovy.

После рассмотрения этих основных принципов получения метаданных для потоков обработки можно представить общую структуру всего универсального пайплайна обработки, основанного на метаданных.
Универсальный поток, основанный на метаданных
Метаданные позволяют управлять процессами через систему, не прибегая к жёстко заданным программным сценариям. С помощью метаданных можно адаптировать систему к новым бизнес-требованиям, например, при изменении форматов данных или добавлении новых источников. Таким образом, при использовании метаданных обеспечивается высокая гибкость и масштабируемость системы.
Для построения такого подхода используется несколько ключевых компонентов, которые и составляют основу универсального потока. Они включают различные блоки, такие как триггеры запуска потока, запросы к метаданным, трансформацию данных и их загрузку в целевые системы. Эти компоненты позволяют создавать универсальную архитектуру для обработки данных, которая будет эффективно работать как с небольшими объёмами, так и с большими потоками данных.
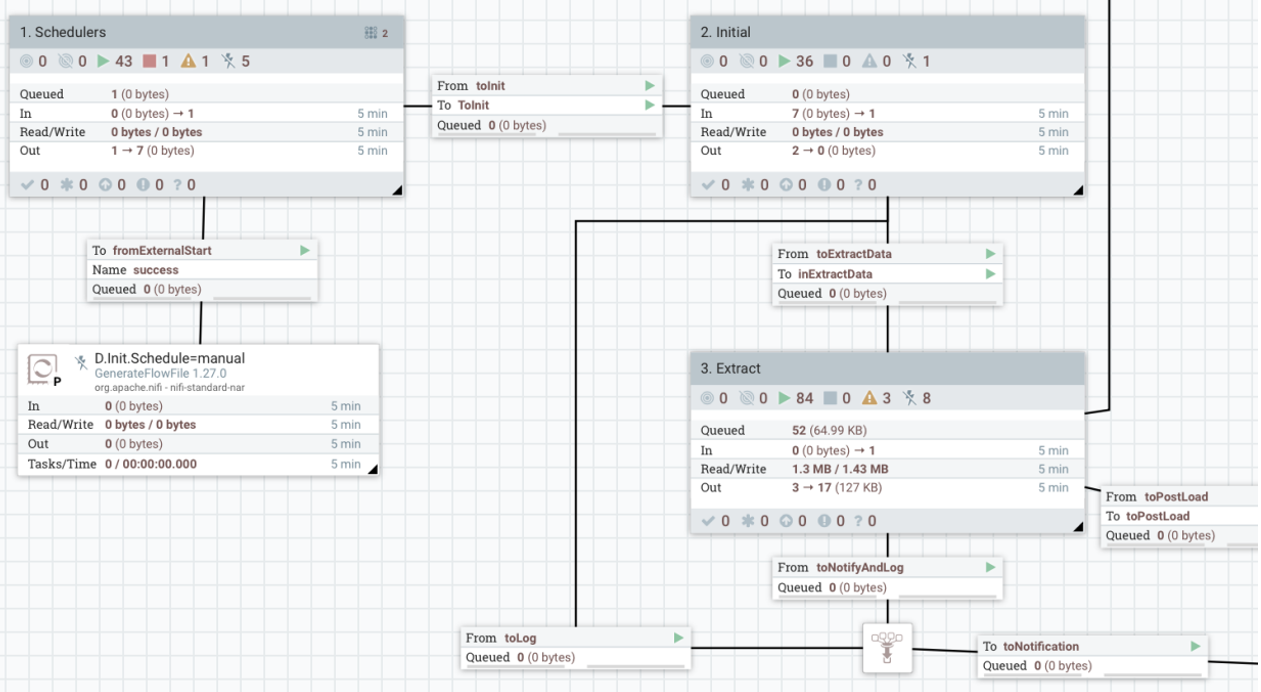
Основные компоненты универсального потока
В универсальном потоке обработки данных, основанном на метаданных, каждый блок выполняет свою ключевую роль в обеспечении гибкости и масштабируемости системы. Рассмотрим основные компоненты этого потока и их функции.
Schedulers: триггеры для запуска потока
Первый блок в универсальном потоке — это Schedulers, ответственный за запуск потока данных. Он включает различные типы триггеров, которые могут запускать поток обработки. Эти триггеры могут поступать из разных источников, таких как:
- GenerateFlowFile — процессор, генерирующий FlowFile для начала обработки.
- HTTP-события — запросы через HTTP, которые содержат данные о том, какой поток следует запустить.
- Сообщения из брокера (например, Kafka) — сообщения, которые инициируют поток.
- Изменения в каталоге — добавление новых файлов или изменения в каталогах, что также может быть сигналом для старта потока.
Init: инициализация потока
Следующий этап — Init, который отвечает за подготовку потока к выполнению. На этом шаге происходит несколько ключевых действий, таких как:
- Запрос к таблице метаданных для получения информации о том, какие атрибуты необходимо сформировать. Например, система может запрашивать информацию о типах данных, которые нужно обработать, или о специфических параметрах для настройки.
- Формирование атрибутов для дальнейшей обработки данных. Это может включать преобразование данных или извлечение значений, которые необходимы для дальнейшей работы в потоке.
- Проверка целевых систем. Перед началом обработки важно убедиться, что целевая система (например, база данных или хранилище данных) готова к приёму данных. Если целевая система недоступна, можно перенаправить данные в другую систему или выполнить отложенную обработку.
- Логирование событий старта. Весь процесс инициализации фиксируется в логах, что позволяет отслеживать, когда и какие данные были загружены в поток.
Extract: извлечение и выполнение запросов
Когда система готова к обработке, на этапе Extract происходит извлечение данных. Этот блок выполняет следующие задачи:
- Генерация и выполнение запросов для извлечения данных из различных источников. В зависимости от типа данных запросы могут быть специфичными для источника (например, SQL-запросы для базы данных) или универсальными для разных типов систем. На основе метаданных система может автоматически сформировать запросы, необходимые для получения актуальных данных.
- Получение данных из брокеров сообщений. Если поток использует брокеров сообщений, таких как Kafka, то в этом блоке происходит извлечение данных, а также их обогащение с помощью метаданных. Это может быть полезно для добавления дополнительной информации, такой как временные метки, идентификаторы транзакций или другие атрибуты, которые требуются для дальнейшей обработки.
- Обогащение данных метаданными. Важно, чтобы полученные данные не только соответствовали формату источника, но и содержали всю необходимую информацию для дальнейших этапов обработки. Метаданные могут включать информацию о типах данных, их структуре или требованиях к целевой системе.
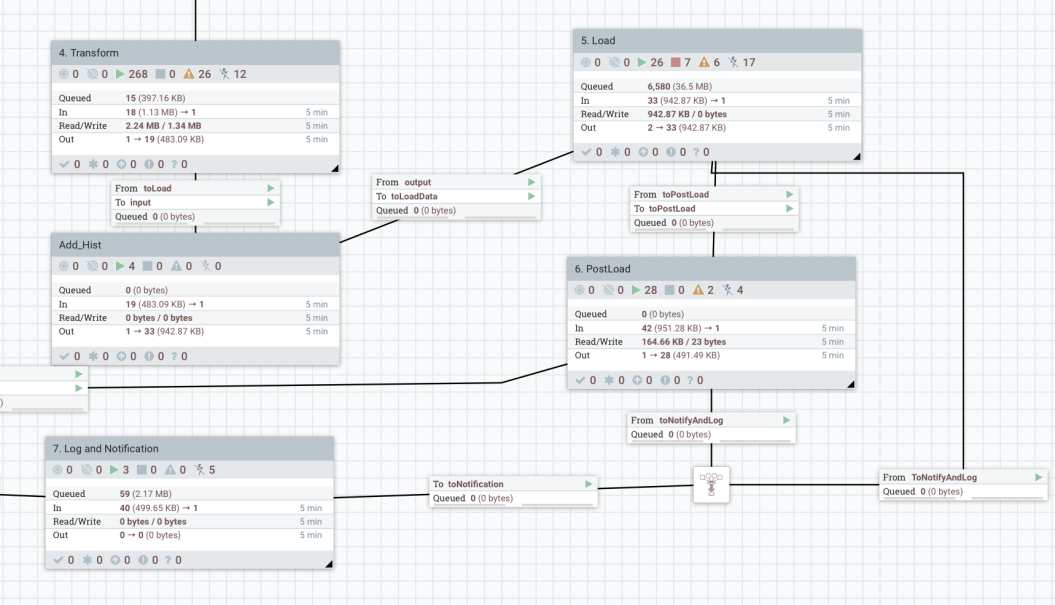
Transform: трансформация данных
После того как данные извлечены, необходимо выполнить их трансформацию, чтобы привести их в нужный формат для целевой системы. В блоке Transform выполняются все необходимые преобразования данных, такие как:
- Конвертация данных в нужный формат. Например, если данные извлечены в формате JSON, они могут быть преобразованы в XML или формат, подходящий для базы данных. Это может быть сделано с использованием различных процессоров, таких как JoltTransformRecord или ExecuteScript, которые позволяют выполнять преобразования на основе метаданных.
- Динамическая настройка трансформаций. Благодаря метаданным, трансформации могут быть настроены гибко. Например, метаданные могут содержать правила для фильтрации или изменения структуры данных, что позволяет адаптировать систему под новые требования без переписывания кода.
- Адаптация под конкретные бизнес-логики. В зависимости от исходных данных метаданные могут содержать информацию о том, какие поля необходимо добавить или изменить, что даёт гибкость в настройке бизнес-процессов.
Этот блок является ключевым для подготовки данных к загрузке в целевые системы, обеспечивая правильную трансформацию и согласование данных с требованиями бизнес-логики.
Add_HIST: сохранение истории изменений
Блок Add_HIST играет важную роль в сохранении истории загрузок и изменений данных. Этот шаг необходим для обеспечения аналитики и аудита, а также для возможности восстановления данных или проведения сравнений в будущем.
- Использование метаданных для сохранения истории. На основе метаданных система может автоматически решать, следует ли сохранять изменения в историческую таблицу или файл. Например, если в метаданных присутствует флаг, указывающий на необходимость ведения истории, данные могут быть записаны в отдельную таблицу или файл с постфиксом HIST, что позволяет отслеживать изменения и сохранять исторические версии данных.
- Обработка данных с сохранением истории. В некоторых случаях исторические данные могут храниться параллельно с текущими, что позволяет проводить сравнительный анализ или использовать старые данные для восстановления информации. Например, если в какой-то момент произошли изменения в структуре данных, важно сохранить их историческую версию для аудита или восстановления.
Load: загрузка данных в целевые системы
После того как данные были обработаны и трансформированы, следующим шагом является загрузка в целевые системы. В блоке Load происходит непосредственная запись данных в конечные хранилища.
- Выбор целевой системы через метаданные. Метаданные играют ключевую роль на этом этапе, поскольку они определяют, в какую систему или формат следует загружать данные. Например, в метаданных может быть указано, что данные должны быть записаны в базу данных, Kafka или файл в определённом формате. Эти данные могут быть направлены в разные системы в зависимости от заданных атрибутов.
- Загрузка в разные форматы и системы. Загрузка может быть выполнена в базы данных, где можно использовать различные механизмы записи данных, включая пакетные загрузки для оптимизации производительности. Также возможно выгружать данные в файл (например, CSV или JSON) или передавать их в потоковое хранилище данных, такое как Kafka, для дальнейшей обработки.
- Поддержка различных типов загрузок. Блок Load может быть настроен таким образом, чтобы подстраиваться под различные требования целевых систем. Например, если целевая система требует определённой формы записи данных или ограничения по скорости загрузки, эти параметры можно задать через метаданные.
PostLoad: завершающие действия
Когда данные загружены в целевые системы, необходимо выполнить завершающие действия, которые могут включать дополнительные проверки и операции для обеспечения целостности данных и корректной работы системы в будущем.
- Логирование завершения работы. В блоке PostLoad фиксируется окончание обработки потока, что позволяет отслеживать успешность выполнения задач и зафиксировать статусы выполнения. Это важно для мониторинга состояния системы и быстрого реагирования на возможные ошибки.
- Обновление метаданных. В некоторых случаях после загрузки данных необходимо обновить метаданные для поддержания актуальности информации. Например, можно вычислить максимальные значения для инкрементов или обновить информацию о текущем состоянии системы. Это может быть важно для корректного функционирования дальнейших потоков.
- Переключение партиций. В зависимости от того, как организована работа с данными, может потребоваться выполнение процедур переключения партиций или других операций с данными, которые обеспечат эффективную обработку и хранение данных в дальнейшем.
LogandNotification: логирование и уведомления
Последний блок потока, LogandNotification, отвечает за фиксацию всех операций, произошедших в процессе обработки данных, и отправку уведомлений о статусе потока.
- Логирование статуса выполнения. В процессе обработки данных важно фиксировать каждый шаг — от запуска потока до его завершения. Логирование помогает быстро диагностировать ошибки и понять, на каком этапе произошёл сбой. Это позволяет оперативно реагировать на проблемы и минимизировать их влияние.
- Отправка уведомлений. Важным элементом является система уведомлений, которая информирует ответственных лиц о завершении потока, успешности выполнения или возникших ошибках. Уведомления могут отправляться через различные каналы, такие как email, системы мониторинга или внутренние чаты.
Преимущества и недостатки подхода
Подход, основанный на универсальном потоке с использованием метаданных, обладает как рядом явных преимуществ, так и определёнными недостатками. Чтобы было проще понять ключевые моменты, приведём их в виде таблицы:
| Преимущества | Недостатки |
|---|---|
| Единый поток для всех систем уменьшает количество процессоров на инстансе NiFi и упрощает архитектуру, обеспечивая большую гибкость. | Затратность на начальной разработке: создание системы, основанной на метаданных, требует значительных усилий для настройки, отладки и оптимизации каждого шага. |
| Универсальная система метаданных, логирования, генерации запросов позволяет централизованно управлять метаданными, что упрощает создание запросов и отслеживание процессов. | Нужны дополнительные системы для хранения метаданных: для эффективного функционирования требуется инфраструктура для хранения и управления метаданными, что добавляет затраты. |
| Известные точки отказов: возможность заранее определить возможные точки сбоев и наладить механизм анализа ошибок для быстрого реагирования на неполадки. | Сложность управления метаданными с ростом количества потоков: когда потоков становится много, возникает необходимость в специализированных средствах для администрирования метаданных, что усложняет управление системой. |
| Быстрое добавление новых источников данных: возможность оперативно добавлять как существующие таблицы/топики, так и новые системы, что ускоряет масштабирование системы. | Проблемы с производительностью на старте: несмотря на гибкость и масштабируемость, начальная настройка и отладка каждого этапа требуют значительных усилий, что может замедлить time to market. |
| Поддержка и развитие требуют одного-двух разработчиков: система становится удобной в обслуживании, и для её поддержки достаточно минимального числа специалистов. | Необходимость в постоянной отладке: каждый шаг в потоке требует тщательной настройки и тестирования, чтобы избежать узких мест в процессе обработки данных. |
| Управление расписанием можно отдать аналитикам: возможность освободить разработчиков от управления расписанием, передав эту задачу аналитикам, что повышает гибкость системы. | |
| Статистика по старту/остановке потоков, размеру загруженных данных позволяет получать полную информацию о процессах, улучшая аналитику и мониторинг работы системы. |
Такой подход предоставляет множество преимуществ, таких как гибкость, универсальность, снижение затрат на поддержку и развитие, а также возможность быстрого масштабирования и интеграции с новыми системами. Но важно понимать, что при его внедрении возможны начальные трудности, такие как высокие затраты на разработку и необходимость в дополнительной инфраструктуре для хранения и управления метаданными.
Итог
NiFi кажется простым инструментом благодаря визуальному интерфейсу, но за ним стоит мощная платформа, которая позволяет строить гибкие, масштабируемые и отказоустойчивые решения для потоковой (и околореляционной) обработки данных. Разобравшись в парадигме FBP, вы сможете быстрее и эффективнее проектировать интеграционные конвейеры, настраивая их под свои бизнес-требования. Особенно это актуально при работе с большими данными и микросервисной архитектурой, когда требуется быстро и безопасно перемещать, обогащать и маршрутизировать информацию из множества источников. Выделив общие элементы в ваших потоках обработки и разработав систему метаданных, вы сможете легко вводить новые таблицы из уже подключённых систем либо добавлять новые системы, сокращая ресурсы на разработку и отладку.
Автор статьи:

Иван Клименко
Архитектор департамента поддержки продаж