
По данным Gartner, плохие данные съедают до 30% годовой выручки, снижая точность отчётности, вызывая ошибки в ценообразовании и замедляя автоматизацию. Исследование Experian показало, что 91% компаний уже ощутили прямой или косвенный финансовый ущерб из-за некачественной информации. В России сходная картина: 72% организаций фиксируют убытки, а треть — прямо указывает на нехватку компетенций в управлении данными.
Почему технологии без методологии не спасут
Даже самые продвинутые инструменты не дадут эффекта, если применять их без системы. На практике компании часто начинают с запуска базовых DQ-проверок (Data Quality, качество данных), но через пару месяцев сталкиваются с тем, что отчёты «краснеют», инциденты не закрываются, а бизнес всё так же не доверяет данным. Причина в том, что проверкам не хватает контекста: нет понимания, какие данные есть в компании, какие из них требуют повышенного внимания с точки зрения их качества и почему не выделены роли, которые отвечают за результат, отсутствуют регламенты по работе с качеством данных, не выстроен инцидент-менеджмент, нет метрик, связанных с бизнес-целями.
Data Quality (DQ, КД) — это подход к обеспечению точности, полноты и актуальности данных в организации. Он включает в себя автоматизированные проверки, мониторинг качества и управление ошибками данных.
Три пробела, которые «съедают» ROI от DQ-софта
- Отсутствие назначенных владельцев данных. При отсутствии ответственных за дата-продукты* — специалистов, определяющих требования как к модели данных, так и к их качеству на всех этапах жизненного цикла, — ошибки накапливаются в цепочке информационных систем, а целостный и системный подход к управлению качеством данных не формируется.
* Дата-продукт — это высококачественный и готовый к использованию набор данных, который сотрудники компании могут с лёгкостью получить и применять для решения разных рабочих задач.
- Неопределённые критерии и целевые пороги качества. Без политики и методик DQ каждая команда трактует «правильные данные» по-своему. В результате метрики не бьются с бизнес-целями.
- Незрелые процессы инцидент- и проблем-менеджмента. Типичные первопричины «грязи» в данных остаются без должного анализа и устранения при отсутствии соответствующих регламентированных процессов и KPI отвечающих за их исполнение сотрудников.
Методология как «операционная система» для инструментов
Методология качества данных DataCatalog закрывает эти пробелы: определяет подходы к приоритизации данных, формализует Data-Contract (дата-контракты), задаёт ролевую модель (от CDO до аналитика), регламентирует жизненный цикл проверок и инцидентов. Только на такой структурированной «почве» DQ-платформы — Arenadata Catalog (ADC) и Arenadata Catalog Data Quality Framework (ADС.DQF) — дают измеримый эффект, а не декоративную отчётность. Попробуем разобрать методологию по полочкам.
Шаг 1. Приоритизация данных
Наращивать качество данных дорого: каждая дополнительная проверка потребляет CPU-время, людей и лицензии. Поэтому игра стоит свеч только там, где «грязные данные» влияют на деньги, регуляторные штрафы или репутацию. Приоритизация данных определяет именно эти критические зоны и превращает бесконечный список таблиц в управляемый backlog.
Как выбираем, что важно
| Драйвер | Примеры вопросов | Почему критично |
| Требования регуляторов | Как исполняются требования положений 716-П ЦБ РФ (банки), 214-ФЗ (девелопмент), 152-ФЗ (ПДн) | Штрафы и блокировка операций |
| Операционные риски и издержки | Сколько денег теряем из-за дубликатов SKU? | Прямая экономия OPEX |
| Управленческая отчётность | Какая выручка по каналам? | Решения C-level строятся на этих числах |
| Аналитика/ML | Какие фичи осуществляют «кормление» моделей? | Некачественные входные данные приводят к дорогому переобучению. |
| Данные-как-продукт | Продаём геоданные, рейтинги, контент | Порча товара = потеря GMV |
Одним из интересных подходов к приоритизации данных является обратный инжиниринг модели DIKAR (Данные, Информация, Знания, Действия, Результаты) — когда анализ начинают не с имеющихся данных, а с желаемого результата и двигаются в обратном направлении.
- Бизнес-заказчик, или стейкхолдер может ничего не знать про качество данных — он отталкивается от бизнес-целей, например хочет снизить операционные риски в рамках исполнения требований регулятора или логистические потери при доставке товаров.
- На втором шаге необходимо определить набор бизнес-метрик, отражающих степень достижения бизнес-целей. Например, снижение числа инцидентов операционного риска до заданного значения или уменьшение логистических потерь в магистральной доставке товаров.
- На следующем этапе определяем, какие дата-продукты задействованы. Для этого можем анализировать требования регуляторов или цепочку создания ценности. К примеру, постановление 716-п ЦБ РФ среди прочего формирует требования к качеству данных в информационных системах применительно к событиям операционного риска. Для этого рассматриваются ключевые бизнес-процессы компании, информационные системы, с помощью которых они автоматизируются, дата-продукты, применяемые в этих системах, а также данные этих дата-продуктов, которые непосредственно используются.
- Выстраиваем систему управления качеством вокруг этих ключевых данных. В итоге это позволяет сфокусировать усилия и ресурсы непосредственно на ключевых данных, которые связаны с бизнес-целями.
Шаг 2. Оценка зрелости процессов и аудит качества данных
Чтобы достичь какого-либо желаемого уровня развития (зрелости) в чём-либо (управление качеством данных тут не исключение), необходимо понять:
- Где мы находимся сейчас.
- Какие усилия нужно приложить, чтобы выйти на следующий желаемый уровень.
- Как узнать, что этот результат достигнут.
Модель зрелости (5 уровней)
За основу оценки бралась модель оценки зрелости процессов управления данными DAMA-DMBBOK.
| Уровень | Ключевые признаки | Типичная боль |
| Ad-hoc | Реактивное «гашение пожаров», ролей и KPI нет | Хаотичные инциденты, «красные» отчёты |
| Повторяемый | Назначены владельцы топ-датасетов, фиксируются дефекты | Ручная обработка, нет единого процесса |
| Управляемый | Формируется реестр проверок, внедрён инструмент DQ | Разрозненные метрики, слабая управляемость |
| Установленный | Отлажены процессы IM, витрины и борды DQ | Высокая цена расширения охвата данных |
| Оптимизированный | Рост доли проактивного предотвращения дефектов, KPI на всех ролях, работают дата-контракты | Фокус смещается на value-engineering, иногда не берутся в расчёт качественные результаты |
Методика проведения оценки
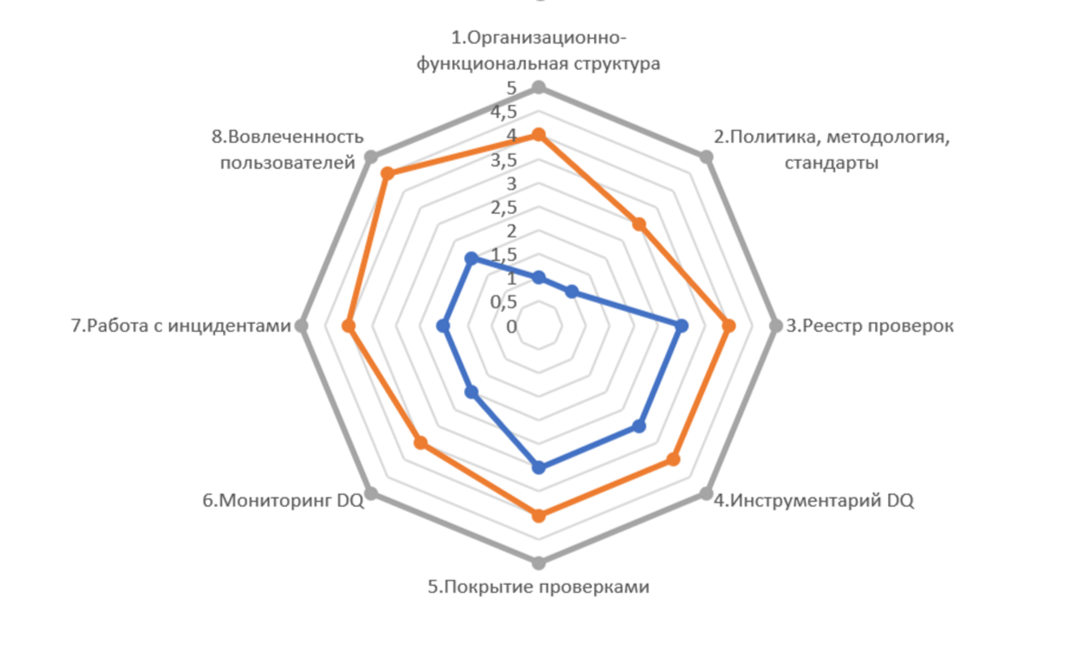
- Анкетирование 360°. Участвуют три среза заинтересованных сотрудников (C-level, middle-management, эксперты), которым на вход подаются анкеты, содержащие вопросы (критерии) по основным направлениям DQ (см. диаграмму). В каждом блоке содержится порядка десяти вопросов. Дополнительно могут проводиться точечные интервью с ключевыми участниками.
- Скоринг. Каждый критерий из пункта выше оценивается в разрезе людей, процессов, технологий по шкале 0…4. Затем в результате средневзвешенной оценки получаем значение по каждому из оцениваемых блоков DQ-диаграммы.
- Экспресс-оценка качества данных. Оценка качества данных является важной частью аудита зрелости, дополняющей анкетирование. Тут есть хорошая аналогия: чтобы поставить диагноз больному, врач сначала задаёт вопросы пациенту относительно его самочувствия и фиксирует ответы. Но потом дополнительно назначает анализы и обследование. Оценка качества — это своего рода анализ состояния данных, «кровеносной системы» компании, который может точно сказать о существующих заболеваниях. Инструментарий Arenadata Catalog позволяет подключиться к источникам данных и сделать необходимую диагностику качества. Для этого есть два подхода — профилирование и тесты качества.
Первый подход даёт базовую оценку состояния данных в источнике: проверяет поля на уникальность и полноту заполнения, формирует статистику по источнику. Второй с помощью тестов качества позволяет организовать бизнес- и технические проверки на точность, согласованность, актуальность и другие показатели.
Результаты оценки
- Отчёт о зрелости функции DQ в организации
- описание текущего и ближайшего целевых состояний зрелости процессов DQ;
- отчёт по качеству данных обследованных источников;
- дорожную карту с горизонтом до года, содержащую список инициатив, KPI, оценивающих достижения заявленных целей, верхнеуровневую оценку бюджета и ресурсов.
Шаг 3. Организационно-функциональная структура для процессов DQ
Организационно-функциональная структура — это система координат, в которой задачи Data Quality становятся чёткими, исполнимыми и измеряемыми. Без неё ни Data Contract, ни реестр проверок не приживутся.
Три базовые модели ответственности
| Модель | Где уместна | Ключевой плюс | Ключевой риск |
| Централизованная (DQ-офис под CDO) | Жёсткие регуляторные отрасли, зрелая DG-функция | Единые стандарты и приоритеты | «Узкое горло» при масштабировании |
| Децентрализованная (DQ-команды в доменах) | Продуктовые диджитал-компании с сильной командной автономией (возможно, с выстроенной в ходе внедрения Data Mesh доменной организацией данных) | Быстрое внедрение в домене | Фрагментация практик, затраты на интеграцию |
| Федеративная (центральная методология плюс доменные владельцы и исполнители) | Аналогично децентрализованной модели, но с более зрелой DQ-функцией | Баланс единства и гибкости | Требует зрелых Data Owners, комитеты по управлению данными |
Распределение ответственности по DQ внутри операционной модели
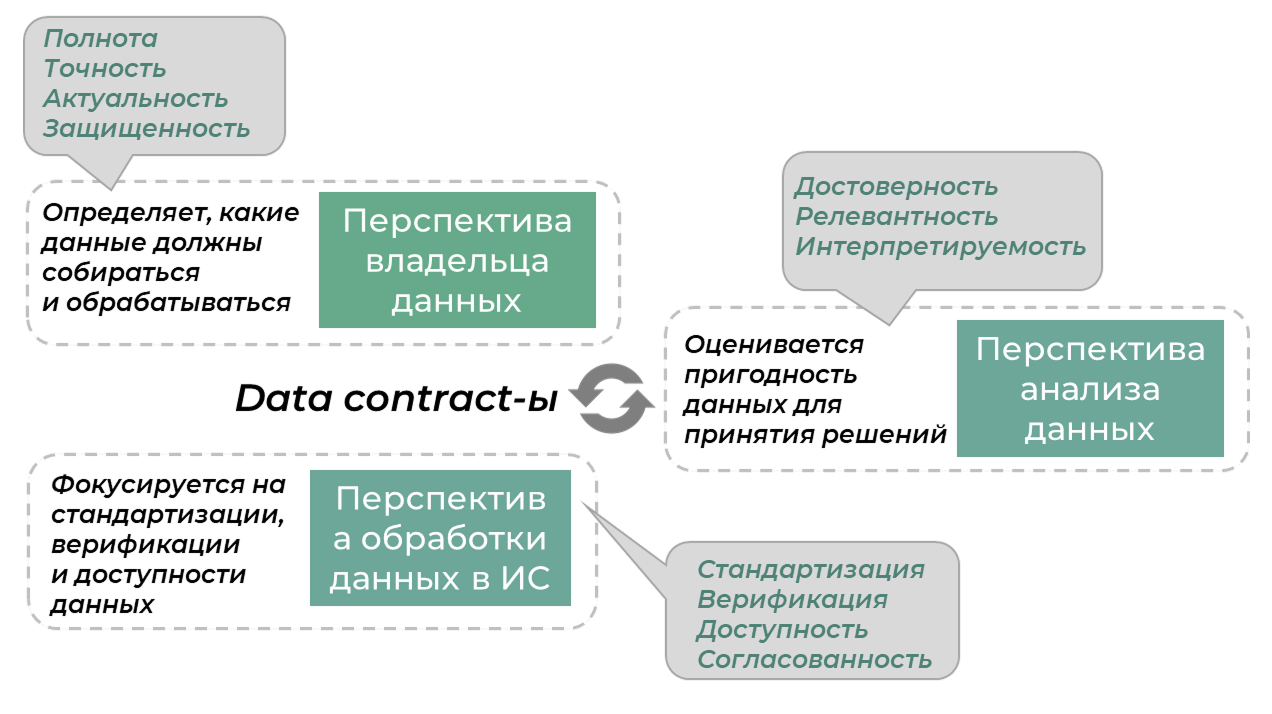
Важный момент, на котором хочется заострить внимание, — распределённая ответственность за реализацию проверок DQ.
Идея состоит в том, что разные роли «смотрят» на одни и те же данные с разных перспектив. И в этих перспективах им «виднее» те или иные аспекты качества данных. Поэтому логично их сделать ответственными за «свои» критерии качества.
Так, например, владелец данных определяет, какие данные подлежат сбору и обработке, каким должен быть их атрибутивный состав и кому они будут доступны. С учётом этого логично, чтобы с точки зрения DQ он отвечал за такие показатели, как полнота, точность, актуальность и защищённость.
ИТ-специалист, реализующий решение, занимается технической составляющей DQ и фокусируется на показателях стандартизации, верификации, доступности и согласованности данных.
Аналитик оценивает пригодность данных для принятия решений. Для него важны показатели достоверности, релевантности, интерпретируемости.
В этой связи задача CDO в части DQ видится не в исправленных данных, а в развитии системы договорённостей о критериях качества и его стоимости.
Роль дата-стюарда по дата-продукту в данном случае будет сводиться к обеспечению исполнения Data Contract, мониторингу их исполнения, контролю за инцидентами DQ и формированию и поддержке реализации инициатив по повышению качества данных.
Data Contract фиксирует эти договорённости: владельцы определяют, какие данные критически важны, ИТ гарантирует их обработку и доступность, аналитики — пригодность этих данных для принятия решений.
Шаг 4. Разработка политики и методик DQ
Политика DQ
Для того чтобы функция Data Quality стала правилом игры, распределение обязанностей между участниками необходимо зафиксировать в виде единого документа — политики DQ (иногда она является частью политики по управлению данными).
Политика DQ закрепляет следующие аспекты:
- Идентификацию критичных для организации проблем с КД и их последствий.
- Подходы к приоритизации данных, выделение дата-продуктов, ключевых данных и бизнес-метрик КД.
- Подходы к выделению показателей качества для обеспечения бизнес-метрик.
- Выбор и обоснование организационной модели в части процессов обеспечения КД.
- Описание ролей и ответственности участников процессов по обеспечению КД.
- Требования к аудиту качества данных в организации.
- Требования к формированию и актуализации реестра проверок КД.
- Требования к мониторингу и отчётности показателей КД.
- Подходы и регламент формирования мероприятий по улучшению КД.
- Требования к инструментам определения и мониторинга показателей КД.
- Построение процесса работы с инцидентами КД.
Методики DQ
Если политика — это более верхнеуровневый концептуальный документ «про договорённости», задающий некую общую законодательную базу (своего рода конституция), то методика DQ — документ более практический, направленный на системное улучшение ситуации с качеством данных в компании. Документ целесообразно разрабатывать в разрезе дата-продукта.
В нём описывается:
- классификация источников и причин дефектов;
- выделение ключевых бизнес-метрик и их связь с показателями качества (бизнес не интересует качество данных);
- выделение целевых значений показателей качества;
- критерии эффективности алгоритмов оценки качества данных;
- проектирование реестра проверок с точки зрения их атрибутивного состава и классификации;
- ведение реестра проверок — описание логики, требований к выполнению и результатам, процесс управления изменениями;
- требования к представлению результатов проверок (показатели, разрезы, элементы визуализации);
- построение процесса инцидент-менеджмента, включая классификация инцидентов, процессы их обработки, проблем-менеджмент.
Ключевой момент: такой важный документ, как методика, должен быть «живым» и не должен оказаться забытым сразу после разработки и согласования. Чтобы этого не произошло, стоит следовать ряду рекомендаций:
- Активно вовлекать в процесс разработки владельца и дата-стюардов по тому дата-продукту, которому посвящена методика.
- Регулярно обучать пользователей-участников процесса, получать от них обратную связь.
- Поддерживать актуальность документа.
Шаг 5. Реестр проверок — «единое окно» требований к качеству данных
После того как мы зафиксировали, какие данные требуют повышенного внимания, выделили роли, назначили ответственных за данные, проработали операционные процессы, закрепили договорённости в политике DQ, проработали методики по работе с качеством данных в разрезе дата-продуктов и источников, пора переходить к практическим шагам. Они начинаются с проектирования и классификации проверок DQ.
Что содержится внутри реестра проверок
Реестр проверок — это формализованное описание правил контроля DQ, их структуры, ответственных и истории изменений. В нём также фиксируется классификация по необходимым признакам, что позволяет получать аналитику в нужных разрезах, например по бизнес-метрике, показателю качества данных, источнику данных, дата-продукту, владельцу дата-продукта, ответственному подразделению или уровню критичности проверки.
Функциональность Arenadata Catalog для ведения реестра проверок
На этапе построения функции Data Quality ведение реестра проверок можно начинать до внедрения специализированного инструментария. Отсутствие платформы не является препятствием: структуру и классификацию проверок можно зафиксировать, например, в Excel. Тем не менее использование специализированного инструмента с самого начала позволяет сразу обеспечить прозрачность, избежать миграции данных на старте, сократить Time-To-Market при запуске новых проверок, а также уже на первом этапе выстроить процесс управления изменениями и поддержки версионности.
ADC обладает обширным набором функций, полностью и качественно закрывающим все необходимые потребности бизнеса по ведению реестра проверок:
- Предопределённый тип данных с базовым набором атрибутов, позволяющий уже «из коробки» работать с сущностью «Проверка качества данных». При необходимости её можно расширять любым числом дополнительных атрибутов по желанию пользователя.
- Функциональность классификаторов позволяет разметить проверки по любым необходимым признакам для последующего использования в поиске и при построении отчётности (см. выше).
- Связь с объектами организационно-функциональной структуры позволяет гибко распределять проверки по ответственным подразделениям, отвечающим за их логику, реализацию и обработку результатов.
- Возможность ролевой настройки даёт способы гибко назначать необходимые роли ответственных владельцев, дата-стюардов, специалистов ИБ.
- Механизм настройки связей обеспечивает привязку проверок качества с описаниями других необходимых объектов ИТ-инфраструктуры, ведущихся в каталоге в бизнес- и техническом слоях, таких как дата-продукты, информационные системы, интеграционные взаимодействия, бизнес-процессы и прочее.
- BPM-движок позволяет настроить процесс управления изменениями при реализации жизненного цикла проверок, оповещать заинтересованных лиц о появлении/изменении проверок.
- Среда взаимодействия предоставляет возможность подписки на те или иные объекты, а также организации обсуждения необходимых проверок заинтересованными пользователями.
Шаг 6. Внедрение инструментария DQ
Внедрение инструментария DQ рассмотрим на примере продуктов Arenadata.
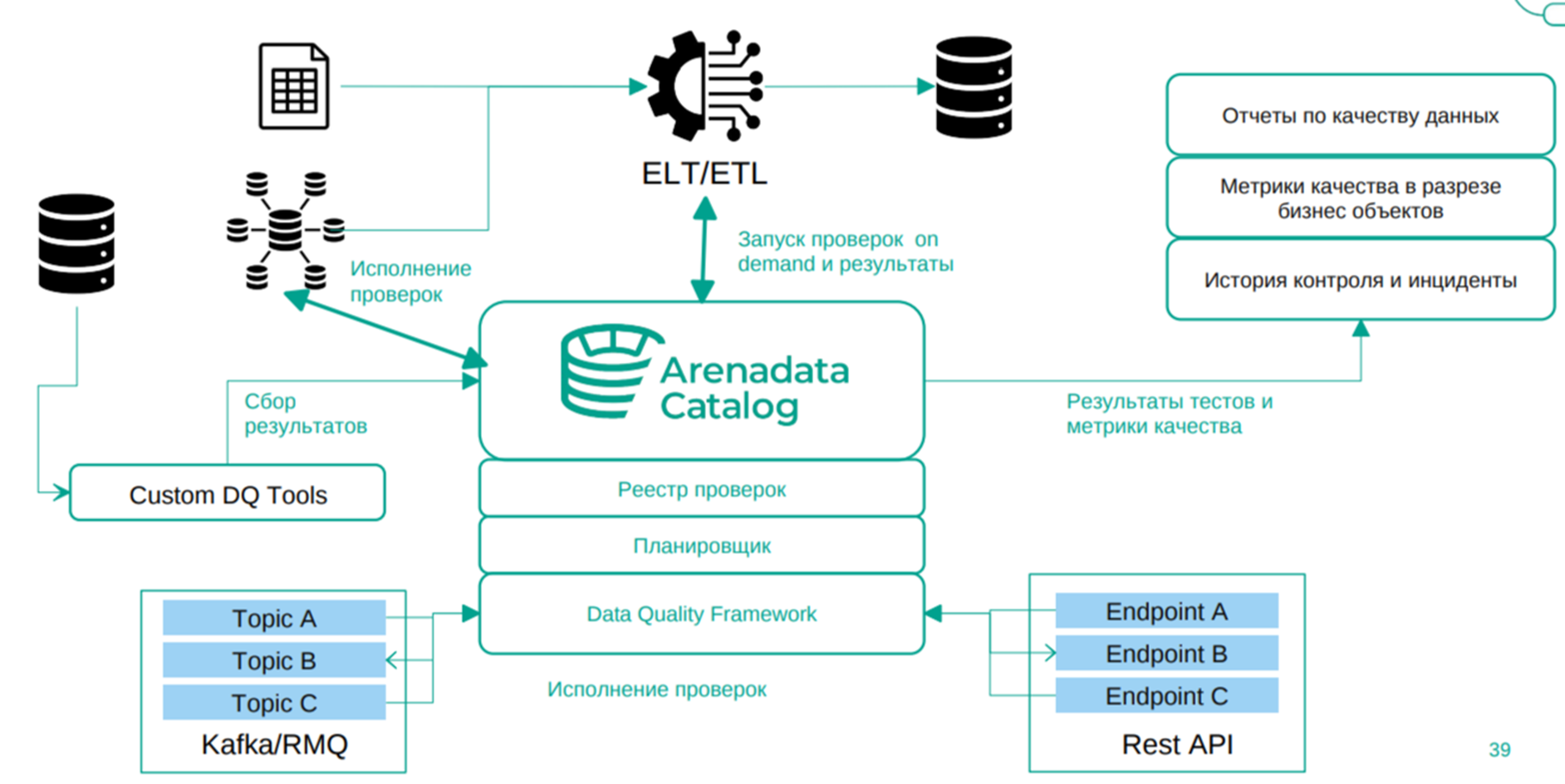
Когда реестр проверок превращается в «единый источник требований», наступает момент подвести под него технологический фундамент. Эта роль разделена между двумя продуктами — ADC и ADC.DQF.
Arenadata Catalog является операционной платформой для DQ, которая управляет метаданными источников и описывает показатели качества вместе с их связью с ключевыми бизнес-целями. Она предоставляет инструменты для ведения реестра проверок (как описано выше) и их реализации в виде шаблонных или кастомных тестов. Платформа также поддерживает профилирование для экспресс-оценки состояния данных, настройку регулярного контроля и работу с результатами проверок.
Поэтому синергетический эффект от функционирования DQ-инструментов на одной платформе с дата-каталогом от Arenadata очевиден.
Arenadata Catalog имеет «под капотом» ещё один важный компонент — Data Quality Framework (ADC.DQF). Используя этот модуль, можно выполнять проверки с агрегированным результатом (количество строк и процент неверных записей), а также проводить профилирование. Эти опции подходят скорее для экспресс-оценки качества данных в источнике. DQF же рассчитан на более сложные сценарии, когда оценка качества превращается в многошаговую задачу: выход одного шага используется на входе другого, а результаты, вплоть до конкретных строк из источника, могут порождать инциденты DQ. Инструмент позволяет разрабатывать проверки с помощью low-code-редактора, а значит, их может создавать человек без навыков разработки.
В ADC.DQF поддерживаются разные режимы исполнения проверок: push-down-запросы в БД источника (по аналогии с ADC), потоковое выполнение с вызовом из очередей Kafka или RabbitMQ, а также контроль на этапе появления данных — DQ Firewall.
Таким образом, связка Arenadata Catalog со встроенным модулем ADC.DQF закрывает широкий спектр задач пайплайна DQ.
Говоря про внедрение инструментария DQ, можно выделить следующие основные шаги:
- проведение процедур сайзинга и анализ инфраструктуры, подготовка пререквизитов для развёртывания;
- инсталляция и настройка ПО. На этом шаге разворачиваются необходимые компоненты (в контейнерах или на bare metal) на требуемое число сред, подключаются и настраиваются источники метаданных и данных, а также проводится финальное тестирование инфраструктуры;
- подготовка и проведение нагрузочного тестирования;
- настройка ролевой модели и прав доступа;
- перенос либо создание «с нуля» реестра проверок, включая связи с необходимыми объектами и процесс согласования изменений;
- реализация необходимых проверок и показателей качества;
- разработка мониторингов качества;
- настройка процесса работы с инцидентами;
- базовая настройка среды взаимодействия (оповещения, подписки и прочее);
- обучение пользователей работе с инструментарием и процессами DQ.
В начале внедрения не стоит пытаться описать и реализовать все проверки, стоит сфокусироваться на тех, которые существуют вокруг приоритетных данных, чтобы дать относительно быстрый и значимый бизнес-эффект (принцип Парето* тут тоже никто не отменял).
* Принцип Парето (правило 80/20) — эмпирическое правило, согласно которому 80% результата достигается за счёт 20% усилий.
Также важно на первом этапе сразу сделать всю необходимую «контекстную обвязку» для проверок DQ — настроить роли участников процесса и распределение прав доступа к источникам и объектам каталога. Выделить показатели качества и понять, как они собираются на основании входящих в их состав проверок. Настроить связи с объектами каталога, в разрезе которых будут формироваться, а затем и мониториться показатели качества — дата-продукты, источники данных, ответственные подразделения, бизнес-продукты и прочее.
Шаг 7. Реализация проверок и показателей качества данных
Этот шаг довольно важный, и о нём следует упомянуть отдельно в разрезе функциональности ADC и модуля ADС.DQF.
Ядром инструмента DQ является расчётный модуль, который получает на вход описание одной или нескольких проверок и массив данных (источник). Он интерпретирует их в понятный машине скрипт, определяет для каждого объекта источника итог проверки и агрегирует полученные данные по заданной логике для расчёта показателей качества.
Говоря о проектировании, следует ещё раз подчеркнуть важность трёх взаимосвязанных возможностей, которые должен поддерживать инструмент DQ: ведение реестра проверок (по сути, требований), простое описание логики с помощью встроенного low-code-редактора и создание шаблонов для многократного использования, в том числе на разных источниках данных. Важным элементом является оркестратор, который позволяет ставить задачи на расписание и выполнять их в нужном порядке. Наличие этих функций обеспечивает прозрачный процесс — от идеи до получения результата — и даёт возможность использовать инструментарий как self-service, доступный не только ИТ-специалистам, но и дата-стюардам, а при определённом погружении и представителям бизнес-подразделений.
Требования к инструменту в части исполнения проверок включают поддержку разных режимов: push-down-запросы в БД источника, вызов из очередей (Kafka, RabbitMQ), контроль на этапе появления данных — DQ Firewall. Это важно, поскольку позволяет контролировать качество и делать сверку данных на разных этапах пайплайна обработки данных, а при ошибке — останавливать его выполнение, чтобы избежать лишних затрат ресурсов, особенно при большом числе пайплайнов.
Шаг 8. Витрины и дэшборды: как превратить цифры о данных в управленческие решения
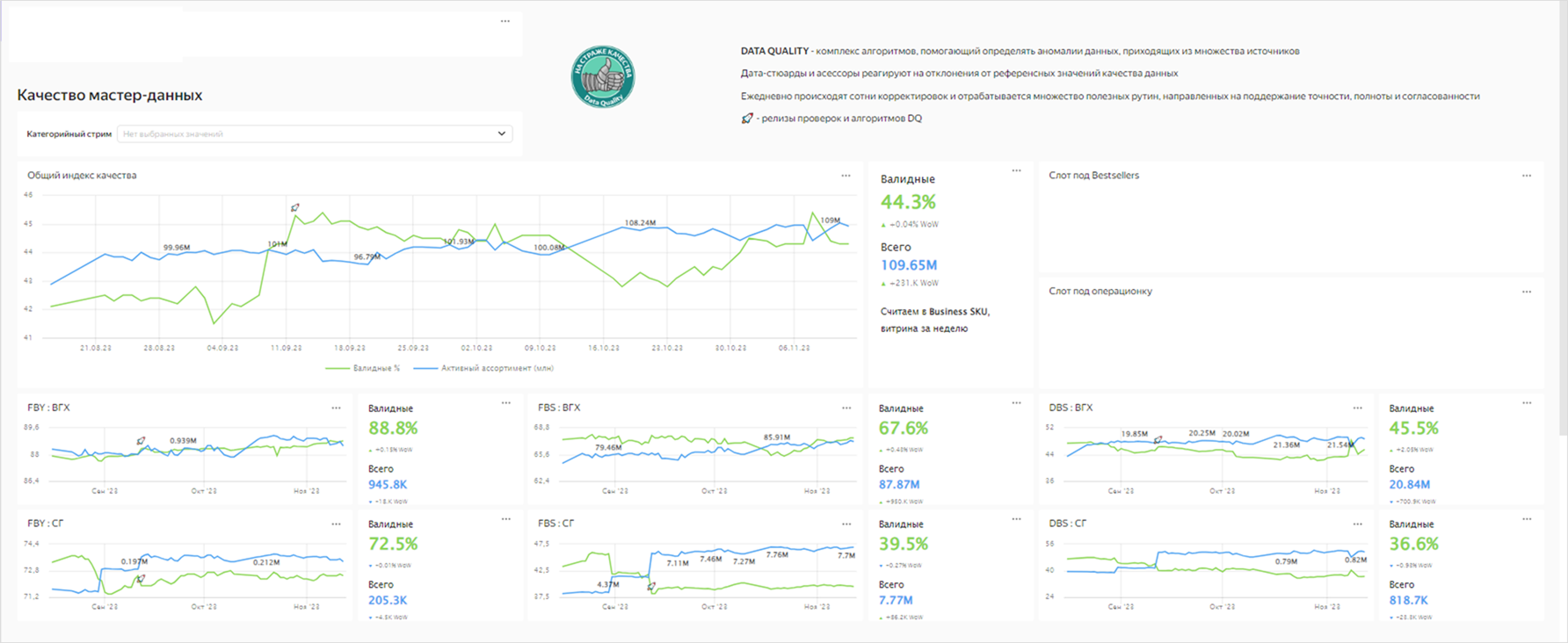
Следующий шаг — настройка мониторингов показателей качества в разных разрезах. Он помогает понять, что происходит с данными, и принять на их основе управленческие решения.
На изображении ниже представлен пример такого борда.
Логика трёх «этажей»
Нижний уровень витрин отражает необработанные результаты — агрегацию строк, не прошедших проверки качества, или зафиксированных инцидентов. Такая детализация достаточна для дата-стюардов и инженеров по качеству данных: они отслеживают отклонения и определяют причины изменений показателей. Это позволяет выявлять как системные проблемы, так и технические сбои в информационных сервисах, оперативно реагировать на них и, при наличии признаков деградации, предотвращать инциденты до их возникновения. Витрины этого уровня содержат расширенный набор отчётов и фильтров, а также поддерживают быстрый переход к результатам конкретной проверки или инцидента (drill-down).
Средний уровень витрин представляет агрегированные показатели качества данных в разрезе дата-продуктов или операционных процессов. На этом этапе в процесс вовлечены операционные руководители и владельцы дата-продуктов. Например, категорийные менеджеры маркетплейса отслеживают точность весогабаритных атрибутов товаров: падение показателя ниже установленного порога ведёт к росту логистических потерь при доставке «последней мили». Директор по CRM оценивает качество контактных данных в мастер-системе клиентов и их влияние на эффективность коммуникаций, например на уровень дозвонов. На этом этапе ключевое значение приобретает не столько сам показатель качества, сколько его связь с бизнес-метриками — именно эта взаимосвязь делает информацию релевантной для бизнеса и позволяет принимать управленческие решения.
Верхний уровень собирает агрегаты всех ключевых дата-продуктов компании и рисует «тепловую карту» для CDO и финансового директора. Их интересуют операционные риски, связанные с качеством данных, а также влияние качества на ключевые финансовые показатели, например GMV, RWA или EBITDA, для принятия системных решений.
Наличие всех трёх уровней управления на основе данных означает, что компания действительно является data-driven.
Техническая реализация
Техническая реализация тут всегда кастомная, т. к. требования к визуализации у разных заказчиков могут сильно различаться. DQ-инструмент должен положить результаты выполнения проверок на требуемых источниках данных в универсальную витрину, где по каждому объекту источника, подверженному проверке, есть свой вердикт. Далее на её базе происходит сбор кастомных витрин с учётом необходимых разрезов и агрегаций, на основании которых будут строиться финальные борды. Эти частные витрины могут размещаться в BI-инструментах или формироваться на основе данных из аналитических СУБД, таких как ClickHouse. Затем на основании данных этих витрин строится система отчётов по показателям качества и ставится на регулярное исполнение.
Шаг 9. Непрерывный цикл инцидент- и проблем-менеджмента
Проактивное и реактивное улучшение качества данных
В прошлом разделе мы говорили о том, как измерить и отразить качество данных в разных разрезах, чтобы принять правильное решение на их основе. Теперь остановимся подробнее на его улучшении.
Оптимальной практикой является предотвращение возникновения инцидентов путём заблаговременного повышения качества данных.
Пример:

Как правило, такая работа реализуется в рамках проектных инициатив, но в отдельных случаях становится частью операционной деятельности и ведётся на постоянной основе. Примером может служить работа с клиентскими данными: процесс включает анализ текущего и целевого состояния по конкретному дата-продукту на основе одного или нескольких источников.
На практике проактивное повышение качества данных удаётся реализовать не всегда. Часто улучшения достигаются в рамках обработки инцидентов, зафиксированных по результатам проверок DQ (реактивный подход). Инструментарий DQ должен обеспечивать идентификацию и классификацию инцидентов, а также их передачу в используемую у заказчика систему обработки. Дополнительно ответственному пользователю необходимо предоставить возможность регистрации инцидента вручную.
Пайплайн обработки инцидента укрупнённо показан на схеме ниже.
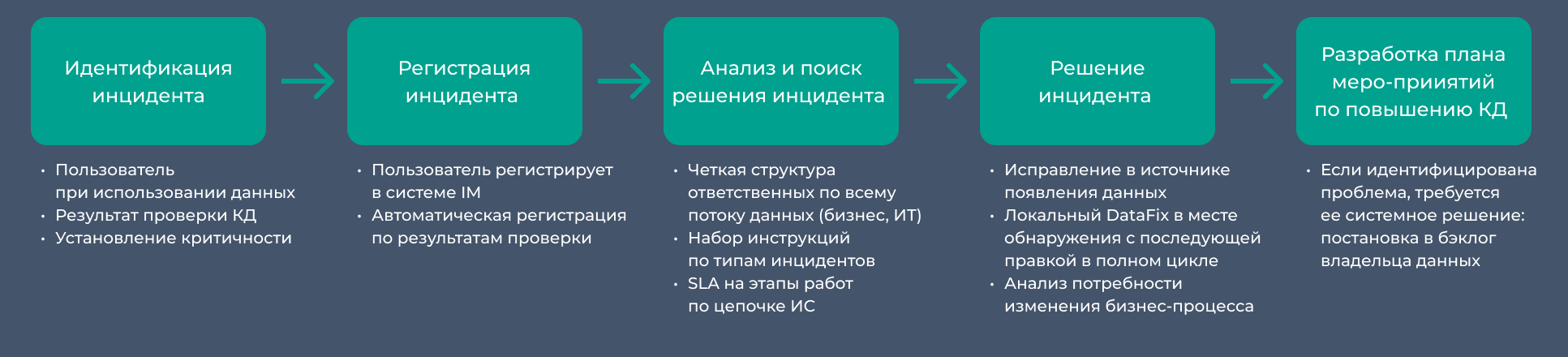
Важной особенностью тут является то, что инцидент или набор инцидентов могут выявить проблему или группу проблем, требующих системного решения.
Далее выявленные проблемы приоритизируются и, как правило, трансформируются в проектные инициативы, охватывающие доработку информационных систем, изменение бизнес-процессов, корректировку моделей и другие меры. Эти действия развиваются по тому же циклу, что и проактивное управление качеством данных.
Надо подсветить ещё один важный аспект: какой уровень качества является достаточным.
Задача управления качеством данных — это всегда непростая дилемма между пользой от качественных данных и затратами на рост качества. Важно помнить: чем выше качество, тем выше затраты на его улучшение на каждый следующий процент. При этом надо понимать, что польза — это про значимый для бизнеса результат. С его выявлением могут возникнуть сложности:
- Не всегда легко посчитать вклад именно роста качества данных в изменение того или иного бизнес-критерия. Например, снижения числа инцидентов с почтоматами, когда туда не влезает посылка, может быть связана не только с ростом качества данных весогабаритов товаров, а с оптимизацией логистических процессов.
- Оценивая эффект от повышения качества данных, следует учитывать не только количественные бизнес-показатели, но и качественные улучшения, которые нередко оказываются более значимыми — например, рост лояльности клиентов, улучшение пользовательского опыта при использовании продукта и другие.
Обнаружить этот баланс — задача непростая, и это всегда результат совместной работы менеджера по качеству/CDO и бизнес-эксперта. Тут верхней отсечкой уровня качества может служить такое значение, для улучшения которого потребуются значительный (экспоненциальный) рост финансовых вливаний или стратегические изменения бизнеса. При этом есть понимание, что если текущее состояние процессов и систем управления DQ, включая в числе прочего инцидент-менеджмент, позволяет выдерживать масштабирование бизнеса (с приемлемыми для бизнеса финансовыми и репутационными издержками), то система находится в относительном равновесии и нужно просто поддерживать данное значение показателя качества.
Например, если показатель качества весогабаритных данных товаров на маркетплейсе (агрегация полноты, актуальности, точности и согласованности) находится на уровне 80% и технические возможности его повышения уже исчерпаны — то есть реализованы необходимые контроли на входе, рассчитывается эталонное значение на основе данных нескольких магазинов, используются сведения с сайтов производителей и выполняются точечные замеры на складах, — то следующий шаг может заключаться во введении штрафных санкций за инциденты, вызванные некорректными входными данными. Такой подход существенно ухудшит пользовательский опыт магазинов и может привести к их оттоку, что противоречит стратегической цели бизнеса по увеличению их числа на маркетплейсе.
В то же время наблюдается такая картина:
- Снижается относительное число инцидентов при росте активного ассортимента.
- Растёт доля типовых инцидентов, закрываемых не дата-стюардами, а менее скиловыми операторами техподдержки, команду которых можно легко масштабировать.
Т. е. система управления качеством стабильна в заданных бизнесом рамках. А значит, можно сказать, что указанный выше порог качества весогабаритных характеристик товаров 80% в данных условиях является целевым.
Служба управления инцидентами DQ
Если говорить о службе, занимающейся обработкой инцидентов DQ, то она мало чем отличается от службы техподдержки (ТП) информационной системы или сервиса. Остановимся на моментах, которые помогут повысить её эффективность:
- Инциденты DQ хорошо типизируются, следовательно их обработка легко поддаётся формальному описанию и автоматизации.
- В связи с этим по большинству типов инцидентов можно привлекать операторов (возможно, даже внешних — аутстафф), а более квалифицированных специалистов — определять на разбор сложных нетиповых инцидентов.
- Обработка многих инцидентов хорошо подаётся автоматизации — если разово обеспечить операторов / специалистов ТП необходимыми скриптами, сервисами и дашбордами, то это сэкономит время и трудозатраты в дальнейшем, а специалисты будут работать в режиме self-сервиса.
- Необходимо предусмотреть не только автоматическое заведение инцидентов из DQ-системы, но и возможность их массового автоматического закрытия. Например, из-за внешнего технического сбоя данные не загружаются в источники в нужный момент, что приводит к провалу проверок DQ и большому числу однотипных инцидентов. Такие случаи должны закрываться автоматически после установления их реальной причины.
- Необходимо на регулярной основе следить за качеством обработки инцидентов, закрываемых операторами и специалистами ТП (выборочный контроль, кросс-проверки, анализ операционных метрик, например количество переоткрытых тикетов). Тут должен быть простой, понятный KPI и его контроль в динамике.
- Мотивация операторов и специалистов на выявление проблем с данными и формулирование предложений по их системному решению (переход от реактивного подхода к проактивному).
Шаг 10. Непрерывный цикл управления качеством данных
Итак, подведём итоги:
- Управление качеством данных — это сложный, дорогостоящий итерационный процесс. Поэтому, приступая к нему, на берегу нужно определить действительно важные данные — те, что влияют на критичные бизнес-процессы; формируют прибыль и устойчивость компании; помогают выполнить требования регуляторов; участвуют в принятии управленческих решений.
- Следует принять за основу правило: бизнесу не интересна тема качества данных, вместо неё стоит определить KPI по качеству, основанный на бизнес-целях и метриках. В этих же разрезах необходимо контролировать его выполнение.
- Функцию управления качеством данных в организации целесообразно развивать итерационно, переходя от одного уровня зрелости к следующему. Поэтому важно регулярно с самого начала проводить аудит зрелости, а его результаты использовать для корректировки и уточнения вектора развития.
- Задумайтесь о распределении ответственности: установите владельцев ключевых дата-продуктов и проработайте с точки зрения организации функциональную и ролевую модели. Пусть каждая роль отвечает за те показатели качества данных, которые ей ближе в силу рода деятельности, а для управления обязательствами можно применить дата-контракты. Закрепите достигнутые договорённости в политике по управлению качеством данных.
- Следует формализовывать требования к проверкам качества данных. Не гонитесь за их количеством на начальном этапе, лучше сразу качественно проработайте контекст.
- Выберите и внедрите тот инструментарий DQ, который максимально полно удовлетворяет вашим требованиям. Важными преимуществами здесь являются единая платформа с системой управления метаданными, ведение реестра проверок и их реализация без программирования (low-code-редактор), поддержка всех основных режимов выполнения (push-down-запросы в БД, потоковое выполнение, контроль на этапе появления данных — DQ Firewall), а также наличие среды взаимодействия участников процесса DQ и заинтересованных бизнес-пользователей.
- Реализуйте регулярные мониторинги качества данных. Продумайте три уровня контроля: для экспертов DQ и технических специалистов; для операционных менеджеров и руководителей направлений; для топ-менеджмента.
- Формализуйте основные типы инцидентов, используйте возможности автоматизации, выделяйте проблематику DQ и формулируйте инициативы по системному решению проблем.
- Вовлекайте в процесс бизнес-пользователей с помощью семинаров, воркшопов, инструментов self-сервиса, каналов обсуждения проблематики DQ и прочего. Такая активность станет важным элементом формирования корпоративной культуры по работе с данными.