
Всего за несколько месяцев команда из нескольких сотрудников смогла перейти к современным методам управления данными: внедрила Data Lakehouse в сочетании с Data Mesh, развернула Arenadata DB (ADB), автоматизировала витрины в Data Build Tool (DBT) и существенно ускорила аналитику. Вместо полуавтоматизированной обработки данных сегодня используется единая, масштабируемая экосистема, позволяющая в разы быстрее отвечать на запросы бизнеса и поддерживать ключевые отчёты практически в режиме near real-time.
В этой статье мы подробно разберём, с какими вызовами столкнулась «Национальная Лотерея» на старте, какую архитектуру выбрала в процессе роста и как организовала работу с данными. Кроме того, поделимся практическими находками, которые могут пригодиться и другим компаниям, стремящимся оптимизировать аналитику и построить прозрачную систему Data Governance.
Проблемы и вызовы до старта проекта
Разрозненная инфраструктура и засилье ручных операций
До внедрения Data Lakehouse в «Национальной Лотерее» архитектура хранения и обработки данных развивалась органично, но без единого централизованного подхода. Накопление информации шло параллельно в нескольких системах, в том числе в ClickHouse и PostgreSQL, что со временем стало ограничивать гибкость и управляемость. Не было чёткого разделения на слои: Landing, ODS, DWH и т. д., не велась централизованная оркестрация и не существовало системы контроля качества поступающих данных.

До внедрения единой платформы отчётность формировалась преимущественно вручную — через Excel и выгрузки из нескольких систем. Такой подход соответствовал первоначальным задачам, но с ростом объёмов данных и количества пользователей стал требовать всё больше усилий на сверку, объединение и актуализацию информации.
При росте числа транзакций и усложнении аналитических задач время отклика базовой инфраструктуры начало увеличиваться. В некоторых случаях сложные запросы на 20–30 млн строк могли обрабатываться от 10–15 минут. В пиковые периоды дата-система могла требовать ручного вмешательства.
Количество пользователей аналитики постоянно увеличивалось, превысив 60 человек, которым требовался оперативный доступ к данным. Без чёткого разграничения ресурсов и без проработанной схемы горизонтального масштабирования (добавления вычислительных и storage-узлов) существующая среда могла замедляться при увеличении одновременных запросов.
Зависимость от внешних интеграторов
Поначалу к проекту привлекли подрядчика, чтобы оперативно установить новые компоненты. Однако оказалось, что погружение во все нюансы корпоративных данных требует постоянного присутствия внутренних специалистов: слишком много специфики, исторических наслоений и кастомных процессов.
Необходимость полноценного Data Governance
Одной из важных задач было создание формализованных стандартов работы с данными. Для дальнейшего роста компании необходимо было привести описание ключевых сущностей, а также внедрить процессы для реестра атрибутов и мониторинга качества данных. Как и в большинстве случаев роста компании, с масштабированием возникли типичные проблемы:
- термины и метрики могли трактоваться неоднозначно. Например, один и тот же показатель «количество активных клиентов» мог рассчитываться по-разному в маркетинге и продуктовом блоке;
- управление знаниями требовало уточнений и систематизации;
- ответственность за данные была размытой, и требовалась более чёткая структура ролей и обязанностей.
Задачи с надёжностью
Поскольку предыдущая архитектура не предусматривала резервные копии на системном уровне, восстановление при сбоях приводило к временным задержкам в аналитических процессах. Также необходимость централизованной системы аутентификации и распределения ролей стала очевидной для повышения уровня зрелости компании.
Зависимость от ручных Excel-отчётов
В компании существовало около 70 регулярных отчётов, которые готовились вручную из разных источников. Каждый из них имел собственную логику и набор формул, что могло создавать дополнительные сложности и риски. При увеличении числа транзакций и расширении перечня аналитических задач нагрузка на аналитиков и бизнес-подразделения стремительно росла. Возникла потребность в едином подходе к формированию отчётности, где бы соблюдались следующие условия:
- автоматическая очистка и консолидация исходных данных;
- управление версионностью расчётных формул и аналитических показателей;
- минимизация ручных операций для сокращения времени подготовки и снижения вероятности ошибок.
Выбор архитектуры: почему Data Lakehouse + Data Mesh
Критерии поиска решений
При планировании проекта руководство «Национальной Лотереи» сформулировало ряд ключевых критериев для будущей архитектуры:
- Высокая производительность при больших объёмах данных. Инфраструктура должна обрабатывать десятки миллионов строк на лету и обеспечивать параллельную работу нескольких десятков аналитиков без падения скорости.
- Гибкость масштабирования. С учётом непрерывного роста клиентской базы и числа транзакций требовалась возможность быстро наращивать вычислительные ресурсы (CPU, RAM) и объём хранилища, не перенося массивы данных вручную.
- Единый подход к управлению данными. Необходима централизованная система, где бизнес-метрики, атрибуты и термины определяются однозначно, а доступ к данным регулируется по понятным правилам.
- Поддержка современных инструментов. Важной составляющей стал переход к self-service для аналитиков, возможность коннектить внешние BI-решения, а также планомерно развивать data-science-проекты.
- Минимизация «легаси-барьеров». Компания намеренно выбрала более современную модель без сохранения устаревших компонентов, чтобы избежать повторяющихся проблем со старыми версиями СУБД и неэффективными ETL-процессами.
«На старте формирования бизнес-глоссария было полнейшее непонимание, с чего начать. Метрики и термины, использующиеся бизнесом, не были сформированы. Для начала было решено обойти весь С-1,2 lvl для сбора информации. После месяца сбора данных всё было сведено в единую систему метрик и терминов в количестве 80+ штук. Каждой метрике были даны определение, владелец и метод расчёта. Также была составлена подробная схема со всеми источниками данных, промаркированы каналы передачи, что, в свою очередь, помогло компании с аудитом весной 2024-го. Такой подход стал ключевым для дальнейшего успеха. Моя рекомендация: всегда начинайте с бизнеса и, главное, не ждите, что ему это надо. Ценность от вашей работы он ощутит намного позднее, но точно ощутит».
В пользу Data Lakehouse
В процессе сравнительного анализа архитекторы данных рассмотрели различные варианты: от классических DWH (Data Warehouse) до распределённого Data Lake с минимальной структурой. Однако было решено остановиться именно на концепции Data Lakehouse. Основные причины:
- Единый уровень хранения (Data Lake) и надстроенный слой управления позволяют сочетать гибкость озера данных и аналитические мощности, характерные для традиционных СУБД.
- Поддержка как batch-, так и near real-time обработки удовлетворяет потребности различных подразделений: от регулярных отчётов до оперативной аналитики.
- Гибкая структура даёт возможность использовать схему «вычисления рядом с данными», что особо актуально при больших объёмах транзакций.
- Единая модель метаданных помогает упорядочить бизнес-термины, визуализовать data-lineage и настройки доступа.
Применение подхода Data Mesh
Поскольку в «Национальной Лотерее» одновременно развиваются несколько ключевых бизнес-доменов, компания выбрала подход Data Mesh в дополнение к общей архитектуре Data Lakehouse. Он предполагает, что ответственность за подготовку данных переходит непосредственно к командам, управляющим отдельными доменами. Каждая такая команда сама определяет структуру своих данных, отвечает за качество и актуальность информации, а также регулирует доступ к ней внутри компании.
Базой для работы доменов служит общая инфраструктура Data Lakehouse, которая задаёт стандарты и правила взаимодействия. Это позволяет обеспечить организованную работу команд и гарантирует, что любые изменения в данных будут согласованными и прозрачными. Таким образом, каждая доменная команда получает возможность гибко и оперативно работать над новыми аналитическими сценариями и фичами без необходимости ожидания одобрения от единой централизованной аналитической команды.
Внедрение подхода Data Mesh позволило значительно повысить скорость реакции компании на изменения и сократить время вывода новой аналитики и витрин данных в эксплуатацию. Если появляется необходимость развивать новые бизнес-направления или запускать дополнительные региональные подразделения, достаточно выделить отдельный домен, предоставив ему доступ к общей инфраструктуре и каталогам данных.
Техническая реализация и инструменты
При проектировании новой платформы команда «Национальной Лотереи» решила не ограничиваться единичными заменами СУБД или ETL-скриптами, а подойти комплексно: выстроить общую архитектуру с учётом DevOps-подходов, IaC (Infrastructure as Code) и современных инструментов оркестрации и трансформации данных.
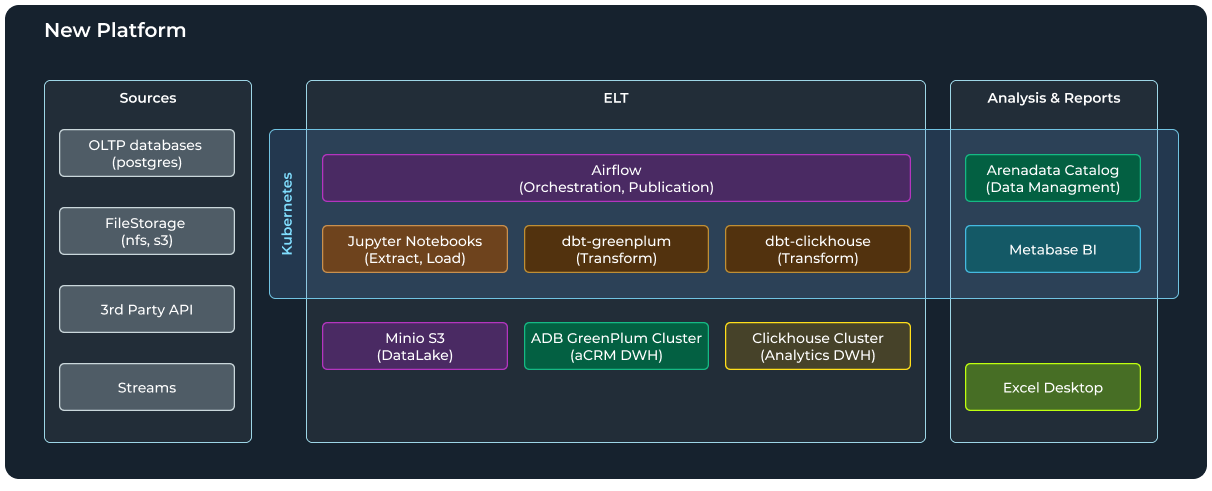
От «зоопарка серверов» к контейнерной среде
В старой инфраструктуре параллельно работали пять виртуальных машин в VMware:
- Airflow;
- ClickHouse;
- Windows-сервер с Python-скриптами для ETL и BI Superset;
- Polymatica;
- дополнительные сервисы для разовых задач.
ETL-процессы порой дублировались: часть шагов запускалась на Airflow, часть — на Windows, а ещё что-то анализировалось в Jupyter. Аналитические отчёты частично базировались на Python + Pandas, частично на запросах к ClickHouse, а где-то продолжали жить Excel-файлы.
Чтобы навести порядок и упростить масштабирование, решили разворачивать основные сервисы в Kubernetes. Этот подход позволил проще управлять ресурсами, настраивать различные окружения (TEST/PROD), параллельно обкатывать обновления. Для автоматизации установок применили ArgoCD, Terraform и Ansible — ключевые инструменты в концепции IaC.
Одним из центральных компонентов новой платформы стала Arenadata DB. Она позволила горизонтально увеличить хранилище и быстро обрабатывать большие объёмы.
Однако в самом начале возникли нетривиальные препятствия.
Нестандартная ОС в компании. Местный ИТ-отдел мог предоставить для ADB лишь среду на Ubuntu 22.04, хотя изначально рекомендовали использовать CentOS/RedHat. Чтобы не замораживать проект, команда Arenadata ускоренно, раньше официального графика выпустила релиз под Ubuntu.
Вызовы ранней версии. Поскольку этот релиз оказался свежайшим, в процессе установки и настройки всплывали необычные баги, которые оперативно решались в рамках технической поддержки.
«Пришлось с нуля создать подходы и методологии, применимые конкретно к данной компании и контексту. Десятки часов, проведённые с дата-аналитиками и BI-аналитиками, позволили спроектировать, оптимизировать и автоматизировать структуру так, что теперь каждый сотрудник компании может её понять, а поддерживать может даже небольшая команда дата-инженеров. В результате смогли полноценно отделить загрузку данных из источников (EL) от их дальнейших преобразований (T) любым инструментом, давая возможность хранения данных в максимально близком к источнику виде, будь то JSON, CSV, Parquet и т. д. Оценив удобство распределённых вычислений, смогли организовать централизованное потребление источников любыми сервисами дата-ландшафта: Greenplum, ClickHouse, Python и т. д., получить в своё распоряжение дешёвое холодное хранилище, в которое можно выгружать исторические данные из DWH и обращаться к ним при необходимости, постепенно и бесшовно перейти к аналитике больших данных при соответствующем росте, используя современные табличные форматы типа Iceberg, получая гарантии ACID в S3».
Несмотря на ввод ADB, в компании решили не отказываться от ClickHouse, который уже неплохо справлялся с рядом оперативных задач и быстрых аналитических срезов. В новой архитектуре распределили зоны ответственности:
- ADB обрабатывает тяжёлые джойны, сложные SQL-запросы, длинные аналитические цепочки;
- ClickHouse отвечает за высокоскоростные выборки, near real-time отчёты и частые короткие запросы, где он показывает лучшие результаты.
Такое разделение позволило повысить общую стабильность: риск «положить» всю аналитику одним неудачным запросом сократился, ведь нагрузка распределена между системами под подходящие сценарии.
Arenadata Catalog (ADC) для управления метаданными
Чтобы централизовать описания бизнес-показателей, data-lineage и правила доступа, в «Национальной Лотерее» развернули ADC. Он выполняет несколько функций:
- Реестр метрик и терминов. В каталоге хранится большое количество ключевых показателей и 30+ терминов, согласованных с владельцами данных.
- Data Lineage. ADC автоматически отслеживает, какие таблицы участвуют в формировании каждой метрики, через какие шаги проходят данные и в каком виде выкладываются в витрину.
- Управление доступами и ролями. Благодаря интеграции с LDAP становится проще управлять разрешениями, а наличие единой модели обеспечивает прозрачность аудита.
Airflow + DBT: переход от ETL к ELT
Раньше скрипты на Python забирали данные из разных источников и формировали промежуточные таблицы, которые напрямую писались в ClickHouse или PostgreSQL. Архитектуру обновили, теперь ключевые процессы выполняются с помощью следующих инструментов:
1. Airflow
- Оркестрация всех задач: расписание, DAG’и, контроль выполнения.
- Раз в сутки или каждые 20 минут для near real-time запускается пакет заданий, который загружает сырые данные, обновляет витрины и рассылает уведомления.
2. DBT
- Описывает трансформации в декларативном стиле.
- Позволяет разбивать логику на отдельные «модели», что упрощает поддержку и повторное использование кода.
- С помощью DBT-Clickhouse и DBT-Greenplum команда теперь может генерировать SQL для обеих СУБД из одного репозитория, автоматически оптимизируя запросы под конкретную цель (ClickHouse или ADB).
При этом сам процесс стал ELT: сначала данные выгружаются «как есть» (Landing), а все дальнейшие преобразования (T — Transform) делаются уже внутри целевых СУБД. В результате удаётся избавляться от громоздких предобработок в Python и использовать SQL-мощности систем.
Metabase как self-service BI
Для визуализации и гибкого конструирования отчётов выбрали Metabase:
- Пользователи из разных департаментов могут самостоятельно создавать дашборды, накладывать фильтры, проводить slice-and-dice анализ.
- Уже создано более 189 дашбордов — их подготовкой занимается 41 активный пользователь: от специалистов Data Office до представителей бизнес-доменов в рамках модели Data Mesh.
- Metabase интегрирован с ADC, что помогает быстро находить нужные таблицы и убедиться, что метрики посчитаны по принятым в компании правилам.
«Я считаю, что BI Self-Service у нас случился, как бы громко это ни звучало! Это стало возможным благодаря простой для понимания, но одновременно гибкой и мощной BI Metabase. Ведь мы даже не провели обучения — не нарочно, мы просто были заняты рефакторингом и настройкой новой платформы. Пользователи научились где-то самостоятельно, где-то им кратко показали аналитики, как использовать систему. С источником мы тоже активно поработали и изначальную витрину детальных продаж увеличили в три раза, что позволяет реже прибегать к использованию SQL-запросов в Metabase, а строить базовые запросы без написания формул и с использованием утверждённых метрик при помощи только одной мыши. Оглядываясь назад, мы понимаем, что на данном этапе развития нашего проекта Metabase оказался очень правильным выбором в противовес другим pixel-perfect BI-системам — они всё-таки сложны для простого пользователя и требуют прямо глубокого погружения и обучения. Ограничения Metabase в оформлении отчётов на самом деле оказываются его сильнейшей стороной: пользователи не думают над выбором из 16 миллионов цветов палитры и подгонкой размеров и положения чартов, а решают свои задачи и принимают решения на основе данных наиболее коротким и быстрым путём».
DevOps, IaC и единая система версий
Все изменения в коде (dbt-модели, настройки Airflow, Terraform-манифесты) проходят через GitLab CI и Merge-request-процедуры.
Это обеспечивает:
- прозрачность изменений: по любому пул-реквесту видно, кто вносит правки, как они повлияют на существующие пайплайны и структуры данных;
- единый процесс деплоя по окружениям: есть TEST и PROD, где сначала всё тестируется автоматически, а уже потом попадает в бой;
- минимизацию человеческого фактора: нет ситуации, когда «кто-то зашёл на сервер и ручками поправил скрипт». Всё фиксируется в репозитории, а деплой запускается в автоматическом режиме.
Таким образом, стек «Национальной Лотереи» обрёл стройную форму: Arenadata DB для глубоких аналитических задач, ClickHouse — для быстрых выборок, Airflow + DBT — для преобразований данных, а Metabase — для BI. Сверху над всем этим работает ADC, который увязывает объекты в единый каталог, устанавливает принципы Data Governance и даёт бизнесу ясность в том, как, откуда и почему берутся метрики.
Data Governance и организационные изменения
Формирование единых стандартов управления данными
Одним из ключевых результатов проекта стало внедрение чётких правил и регламентов, определяющих работу с данными в разных подразделениях. В рамках Data Governance были достигнуты следующие цели.
Утверждение общих метрик и бизнес-терминов
- Все ключевые показатели получили формализованное описание и место хранения в ADC.
- Каждая бизнес-функция согласовала свои определения, чтобы исключить расхождения и дублирование.
Определение ролей и зон ответственности
- Введены роли «владельцев данных», ответственных за конкретные домены.
- Закреплены «стюарды данных», которые контролируют корректность метаданных, проверяют качество, инициируют изменения.
- Прописаны правила эскалации и согласования в случае конфликтов по терминам и отчётам.
Организация регламентов доступа
- Оформлена модель разграничения прав (RBAC) в сочетании с политиками безопасности, учитывающими персональные данные и внутреннюю классификацию.
- Интеграция ADC с LDAP-сервером (или аналогичной службой директорий) упростила единый вход пользователей и единое администрирование.
Культурный сдвиг и самостоятельная аналитика
С приходом Data Mesh в компании поменялся и подход к тому, как бизнес-подразделения взаимодействуют с аналитикой.
- Доменные команды сами готовят свои витрины и дашборды в рамках принятых стандартов. Они лучше знают нюансы своих процессов и могут быстрее обновлять логику расчётов без долгих согласований с центральным отделом.
- Обмен знаниями упростился благодаря ADC: если одному домену нужна метрика другого, всё равно действует единый справочник и двойной расчёт («изобретение велосипеда») исключается.
- Self-service BI (Metabase) укрепил культуру самостоятельных запросов: маркетологи, финаналитики, продукт-менеджеры научились делать собственные срезы и тестовые отчёты. Ранее всё это шло через IT или аналитиков, а теперь в несколько кликов можно построить диаграмму или проверить гипотезу.
В результате бизнес-пользователи получили не только оперативный доступ к информации, но и механизмы самостоятельного создания сегментов клиентов, корректировки метрик и других аналитических сценариев.
Ускоренный онбординг новых сотрудников
После внедрения продуктов Arenadata сократилось время адаптации новых сотрудников. Это произошло благодаря тому, что в компании появился централизованный каталог данных с чётко структурированной информацией о таблицах, отчётах и метриках. Теперь новым специалистам проще разобраться в том, откуда поступают данные и каким образом формируются показатели, поскольку каталог также позволяет отследить происхождение данных (data-lineage). В дополнение к этому унифицированные инструменты оркестрации — DBT и Airflow сделали процессы обработки данных более понятными и прозрачными.
Кроме того, единая система разграничения прав доступа (LDAP) упростила процедуру выдачи и отзыва доступов. В результате время на включение новых сотрудников в рабочие процессы уменьшилось на 30–40% по сравнению с предыдущим подходом, когда они самостоятельно разбирались во множестве неструктурированных Excel-файлов и разрозненных источников.
Влияние на бизнес-процессы и принятие решений
Помимо внутренних технологических изменений, серьёзно изменился и процесс принятия решений.
- Прозрачность ключевых показателей. Руководство и менеджмент, имея доступ к единому набору актуальных отчётов, могут ежедневно оценивать динамику продаж, активность клиентов и финансовые метрики.
- Сокращение ручной рутины. Освобождение аналитиков от постоянной подготовки отчётов позволило им сконцентрироваться на поиске новых гипотез и более глубоком анализе.
- Устранение нестыковок в цифрах. Общие определения терминов и показатели в каталоге минимизируют споры о том, чья цифра правильнее, поскольку вся отчётность опирается на одну версию данных.
Автоматизация и оптимизация бизнес-процессов
Ускорение аналитических запросов
Как мы уже упоминали, при росте числа транзакций и усложнении аналитики, запросы, особенно на выборках в десятки миллионов строк, могли обрабатываться до 20 минут. Теперь подобная нагрузка обрабатывается за секунды или считанные минуты во многом благодаря правильному распределению задач между ADB и ClickHouse, а также переходу к декларативным моделям в ADT, где система автоматически генерирует более эффективный SQL.
Сокращение времени обновления отчётности
Ключевые отчёты, например ежедневные сводки по продажам, раньше формировались вручную по нескольку часов — этот подход оправдывал себя при умеренных объёмах, но по мере роста компании появилась потребность в автоматизации и ускорении процессов. Сейчас инкрементальные загрузки в DBT запускаются каждые 20 минут и занимают всего 5–10 минут на актуализацию данных — аналитики всегда видят практически свежие цифры.
Оптимизация витрины продаж и 75-кратное ускорение
Команда провела глубокий рефакторинг основной витрины: в DBT разделили процесс расчёта на несколько этапов, оптимизировали сортировку и типы колонок: например, применили LowCardinality к текстовым полям. В результате размер таблицы сократился с 80 ГБ до 45 ГБ, а время полной загрузки — с 4,5 часа до 1,5. Витрина, успешно работавшая ранее, уступила место новой, ещё более производительной версии — и это позволило добиться впечатляющих улучшений в скорости и стабильности.
- Среднее время (медиана) запроса уменьшилось в 75 раз
- Количество ошибок выполнения в месяц сократилось в 7,5 раз
- Ошибки из-за переполнения памяти снизились в 2 раза
Минимизация ручных операций и риска ошибок
Теперь все важные отчёты, включая финансовые и маркетинговые сводки, формируются автоматически. Airflow регулярно запускает пайплайны, а DBT следит за корректностью расчётов и материализует финальные витрины. Это практически сводит к нулю человеческий фактор, когда любая опечатка в Excel грозила «положить» итоги дня.
Стабильность при пиковых нагрузках
Модели и пайплайны тестируются в среде TEST, прежде чем попасть в продуктив (PROD). Партиционирование и продуманная схема хранения позволяют избежать частых «выкладок» базы при больших джойнах. Если и возникает сбой, Airflow мгновенно присылает уведомление о том, на каком шаге всё остановилось.
Сокращение ошибок и переполнений памяти

По мере усложнения задач стали заметны ограничения старых подходов: время отклика увеличивалось, особенно при неэффективных SQL-запросах, несовместимости версий СУБД и отсутствия тестовой среды. В ходе внедрения:
- обновили версии платформ (ClickHouse и Greenplum), что помогло избежать ряда известных уязвимостей и багов;
- перенастроили физические структуры (партиционирование, индексы), уменьшив пиковую нагрузку;
- ввели Dev/Stage/Prod-контуры, чтобы любые крупные изменения проверялись заранее.
Итоги и дальнейшее развитие
1. Переход к near real-time обработке (стриминг)
Некоторые задачи (например, online-мониторинг активности игроков или оперативная anti-fraud-аналитика) требуют минимальных задержек и мгновенной реакции. Для этого планируется:
- внедрить Kafka и в режиме потоковой обработки передавать события из онлайн-платформ;
- параллельно обновлять витрины в Arenadata DB или ClickHouse с небольшим лагом (считаные секунды/минуты);
- реализовывать триггерные механизмы: при подозрительной активности сразу же включать дополнительные проверки, не дожидаясь ночного пересчёта данных.
2. CDC (Change Data Capture)
Сейчас многие инкрементальные загрузки вынужденно берут часть последних нескольких дней, чтобы не пропустить обновлённые записи. Это даёт дополнительную нагрузку на исходные базы и постепенно становится «бутылочным горлышком». Поэтому в планах — переход на CDC, когда система умеет отлавливать только изменившиеся строки (insert/update/delete).
- Уменьшение нагрузки на источник: не нужно читать данные за большой период, а лишь фиксировать конкретные изменения в режиме реального времени (или почти реального).
- Ускорение пайплайнов: даже при росте объёмов история уже хранится в Lakehouse, а в источнике лежит только актуальная часть.
- Повышение точности: меньше риск пропустить какие-то обновления или продублировать записи, если правильно настроена логика CDC.
3. Усиление data-science-направления
Фундамент в виде Data Lakehouse (хранилище исторических данных, метаданные в ADC) открывает дверь к более масштабным DS/ML-проектам:
- рекомендательные системы для персонализации оферов и маркетинговых кампаний;
- прогнозирование оттока игроков, анализ поведения клиентов в пограничных ситуациях;
- динамическое ценообразование тиражей или дополнительных игр.
Благодаря автоматизированным пайплайнам (Airflow, DBT) и единому каталогу, дата-сайентисты смогут быстрее получать тренировочные выборки, фиксировать версии моделей и тестировать гипотезы. В перспективе такие сервисы планируют интегрировать в общий конвейер, чтобы свежие результаты моделей напрямую попадали в витрины и далее в Metabase.
4. Геораспределённая архитектура и Disaster Recovery
Сейчас платформа развёрнута в основном в одном ЦОД, однако бизнес «Национальной Лотереи» требует высокой отказоустойчивости и быстрого восстановления при сбоях. Поэтому в планах:
- резервный кластер в другом регионе, который сможет взять на себя часть нагрузки или полностью заменить основной узел при серьёзном инциденте;
- репликация данных в реальном времени, чтобы даже в случае аварии не терять транзакции;
- регулярное тестирование DR-сценариев: проверять, насколько быстро действительно удаётся «поднять» аналитику в случае падения.
5. Расширение Data Mesh на новые домены
Пока data-mesh-модель охватывает лишь основные направления: продажи, финансы, онлайн и т. д. В будущем она может распространяться и на дочерние проекты, партнёрские программы, региональные отделения. Каждая команда получит необходимую автономию, но при этом будет использовать общий язык метрик и единое пространство каталогов.
Итоги
Реализация Data Lakehouse вместе с Data Mesh и продуктами Arenadata в «Национальной Лотерее» стала важным шагом вперёд в цифровой дата-трансформации. Существенно повысилась производительность команд бизнеса, сократилось время на формирование аналитики, а культура управления данными получила сильный толчок. В перспективе развитие real-time-аналитики и datascience-подходов позволит компании оставаться конкурентоспособной в динамичном рынке игорных и развлекательных услуг.
Источник: Блог Arenadata на Хабре
Задать вопрос о проекте