
Отвечая на потребность заказчиков в высокопроизводительном анализе больших данных, хранящихся в системах, развёрнутых на Arenadata Hadoop, Arenadata включила в состав очередного обновления Apache Impala — распределённый сервис исполнения SQL-запросов. Он предназначен для массивно-параллельной обработки (МРР) сверхбольших объёмов данных. Impala разработана как более быстрый и эффективный механизм выполнения SQL-запросов в сравнении с традиционными компонентами SQL-on-Hadoop (Hive, Spark SQL). Поддержка нового сервиса существенно повысила производительность продукта для ряда бизнес-сценариев, в том числе так называемых песочниц данных для внерегламентной обработки информации аналитиками.

«Ряд текущих и новых заказчиков Arenadata воспользовался возможностью ускорения SQL-обработки и анализа данных за счёт использования Impala вместо Hive в озёрах данных. К сожалению, отсутствие поддержки этого сервиса в Arenadata Catalog сдерживало часть из них от переключения нагрузки на Impala в промышленном контуре. Оперативная разработка и поставка коннектора метаданных обеспечила неразрывность отслеживания метаданных в системах и устранила это препятствие».
Особенность применения коннектора Impala
Метаданные объектов интегрируемых систем являются основой каталога данных. Интеграция метаданных объектов Impala позволяет пользователям Arenadata Catalog получать актуальное и полное представление об объектах сервиса, чтобы включить их в граф обработки данных (lineage), исследовать связи с объектами других систем-источников, а также связать с задействованными бизнес-сущностями организации. Администратор Arenadata Catalog может дополнить автоматически собранные метаданные Impala расширенным описанием, сопроводив их пользовательскими атрибутами. Точно так же, как остальные объекты в Arenadata Catalog, объекты сервиса Impala могут иметь владельца и быть классифицированы по уровню бизнес-критичности.
«Технологический ландшафт хранилищ данных российских предприятий отличается высокой сложностью и фрагментарностью. В прошлом для построения КХД широко использовались корпоративные продукты зарубежных вендоров, сейчас развиваются и внедряются решения на базе открытого программного обеспечения. В долгосрочной перспективе программное обеспечение отечественного производства будет занимать преимущественные позиции. Именно по этой причине Arenadata Catalog регулярно расширяет список коннекторов к популярным источникам данных и платформам независимо от их типа, разрабатывая их самостоятельно. Мы стремимся, чтобы Arenadata Catalog стал стандартом де-факто для всех потребителей, строящих хранилища на базе Hadoop, и упростил миграцию на российские решения. Коннектор к сервису Impala из пакета ADH — это очередной шаг в этом направлении».
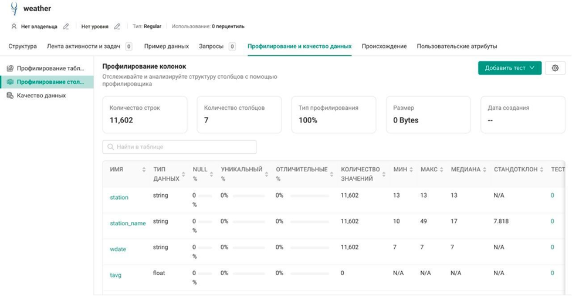
Для Apache Impala возможно сформировать визуальное происхождение данных (Data Lineage) между таблицами и представлениями, в том числе поколоночный lineage.
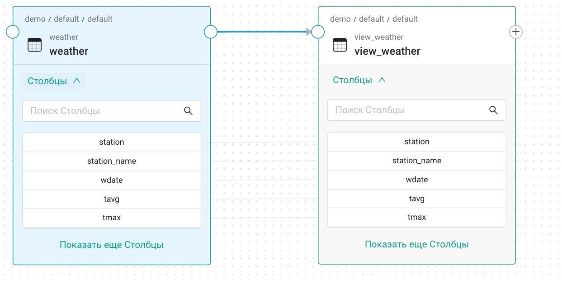
Теперь, просматривая аналитический отчёт, можно с лёгкостью отследить путь преобразования данных между системами: какие атрибуты каких таблиц какой базы данных передали информацию, как в свою очередь они её получили, какие другие информационные системы причастны.
Чтобы запросить демонстрацию функционала каталога данных Arenadata Catalog с коннектором Impala, напишите нам на почту info@arenadata.io.
Возможности Arenadata Hadoop
Arenadata Hadoop (ADH) — корпоративный дистрибутив на базе Apache Hadoop, предназначенный для хранения и обработки слабоструктурированных и неструктурированных данных. Решаемые задачи:- Хранение и обработка больших объёмов слабоструктурированных и неструктурированных данных любого типа (системы управления документами и контентом, хранение и регистрация событий, данные датчиков, каталоги товаров, резервное копирование других СУБД).
- Распределённая обработка информации.
- Построение озёр и фабрик данных (единый центр всех данных компании, быстрое развёртывание и сворачивание «песочниц» для пилотных проектов и проверки статистических гипотез, работа с аналитическими инструментами в единой среде).
- Машинное обучение и искусственный интеллект.
- Источник данных для КХД.
- Импортозамещение западных систем.
1В тестировании использовалась версия Arenadata Hadoop 3.2.4_arenadata2_b1-1 c Impala — 4.2.0_arenadata1 и Arenadata Catalog v.0.6.3.1
Подпишитесь на нашу рассылку и получайте полезную информацию прямо на электронную почту
Новостная рассылка 1 раз в месяц. Отправляем только самое интересное: топовые статьи в СМИ и на Хабре, записи мероприятий, приглашения на ивенты и самые важные новости.
Будем рады помочь!
Отправьте ваш вопрос через форму ниже, и наши специалисты свяжутся с вами в ближайшее время.