
Время + данные = выгода
Любая крупная компания, начинающая работать с данными, которыми обладает, преследует одну первостепенную задачу: получить из них выгоду. При этом ценность данных напрямую зависит от времени, которое требуется на их анализ, обработку. Именно эта зависимость влияет на то, какое архитектурное решение наилучше подойдёт для реализации конкретных задач бизнеса.Чтобы проследить зависимость ценности данных от времени, рассмотрим абстрактный график (рис. 1). Его левая часть демонстрирует данные, возникающие в режиме реального времени в системах источников. Поскольку это крайне динамичный процесс — речь может идти о миллисекундах и секундах, важно научиться эти данные обрабатывать.
Правая часть графика показывает данные, которые накапливает организация. Именно в ней содержится основная историческая ценность: все паттерны поведения различных клиентов, устройств.
Средняя часть графика представляет наименьший интерес с точки зрения получения выгоды. Данные возникают слишком быстро, и мы не можем реагировать на их обработку оперативно, либо данных недостаточно, и мы не получаем качественную статистическую выборку.
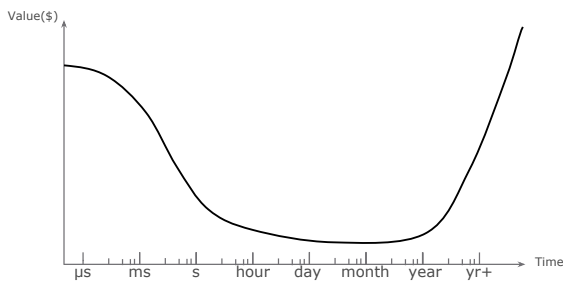
Рис.1
Учитывая зависимость данных от времени, поговорим о пяти подходах к построению платформы данных.
Традиционный подход к построению платформы данных
Что это такое. Традиционный подход к построению платформы данных берёт начало в конце 1980-х годов. У его истоков стояли Билл Инмон и Ральф Кимбалл. В основе их концепции лежит подход, использующий множество реляционных, структурированных источников данных (рис. 2).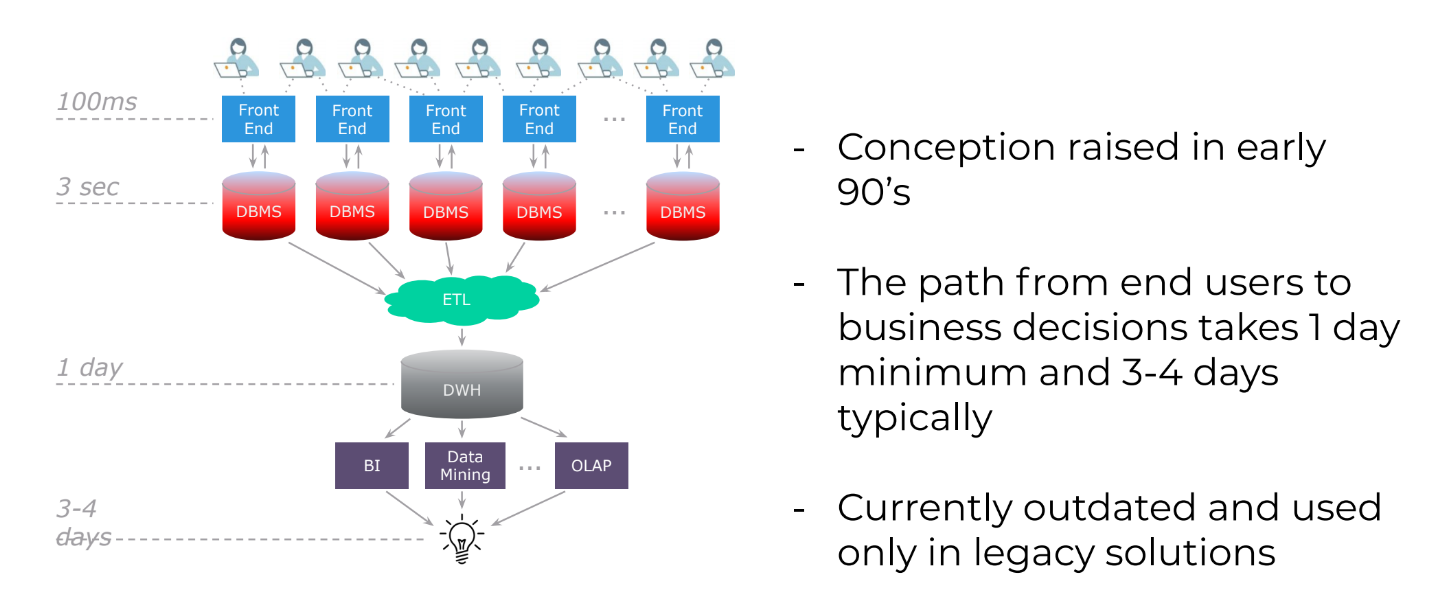
Рис.2
Как работает. ETL-инструмент извлекает данные систем-источников, в процессе чего обрабатывает их, преобразует и загружает в централизованное хранилище данных. На базе этой информации строятся витрины данных, и конечный пользователь в виде BI-систем, процессов Data Mining, OLAP получает какую-то конкретную выгоду.
Основные ограничения. Наиболее актуальная проблема традиционного подхода к построению платформы данных заключается в том, что с момента возникновения данных во front-end системе до момента получения выгоды проходит значительное количество времени. Несмотря на то что в процессе эволюции этот период сократился с 3-4 дней до 1 дня, на текущий момент это всё ещё «очень долго». А любое изменение на источнике или перемены требований со стороны бизнеса влекут «дорогостоящий» процесс по переработке структуры данных хранилища и необходимости получения истории из источников.
Именно поэтому традиционный подход к построению платформы данных редко используется в самых новых проектах (greenfield-проектах). Но многие компании продолжают его эксплуатировать, несмотря на текущие ограничения.
Вторая проблема традиционного подхода к построению хранилища данных заключается в сложности обеспечения отказоустойчивости в случае потери самого ландшафта или инфраструктуры, которые используются под хранение данных. Восстановление системы может занимать несколько дней. Это происходит потому, что помимо основного контура, где наблюдается отставание систем-источников, приходится использовать резервный контур, который ещё больше отстаёт. Поэтому крайне сложно получить актуальные данные в случае выхода из строя каких-то частей основного ЦОД.
Третье ограничение традиционной платформы данных в том, что она может обрабатывать только структурированные данные. Данные другого типа не используются.
В качестве технологий хранения, как правило, использовались Single-Node Processing (SNP) БД: такие как Oracle, SQL Server и их аналоги. В связи с этим масштабирование платформы и архитектуры предполагало Scale-Up подход, когда при достижении пика производительности необходимо было заменять практически всю инфраструктуру.
Пример использования. Традиционная архитектура использовалась практически во всех компаниях на заре работы с Big Data в середине 2000-х годов, особенно в финтехорганизациях. Наиболее крупные хранилища могли исчисляться десятками терабайтов.
Advanced Architecture
Что это такое. Advanced Architecture возникла более 15 лет назад и является модернизированной версией традиционного подхода к хранению данных. Отличается она тем, что конечная система может получать данные, которые измеряются часами или даже десятками минут (рис. 3).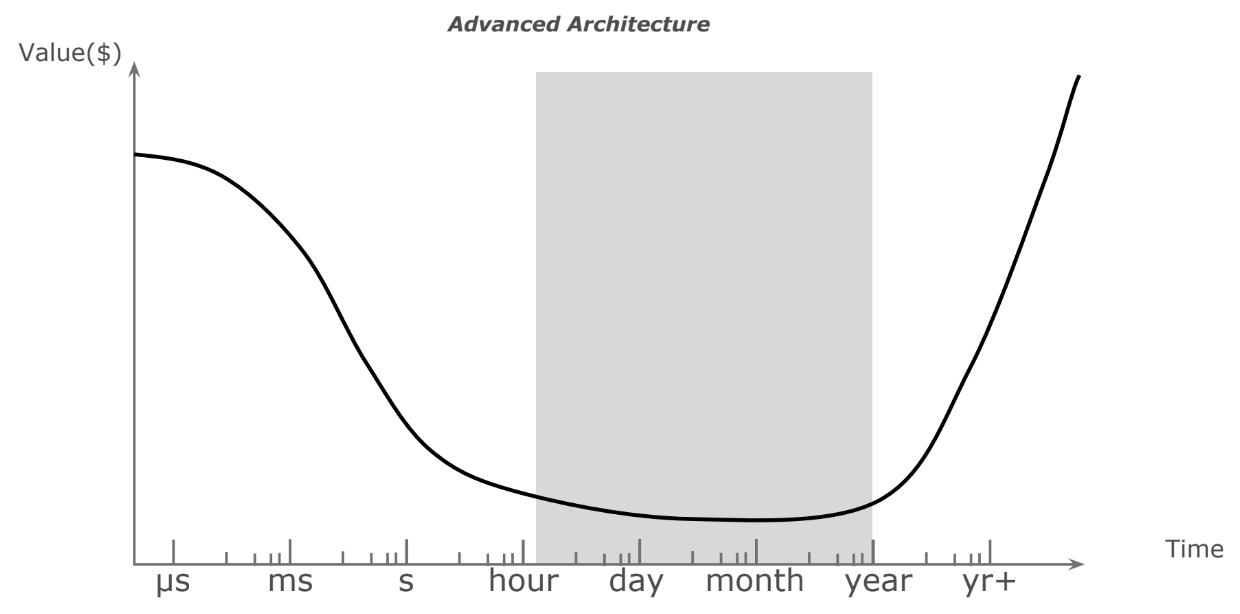
Рис.3
Как работает. В ход пошла ELT-технология: сначала данные извлекаются и загружаются в конечную систему, и лишь после этого происходит их преобразование. Advanced Architecture даёт возможность получить копию исходных данных систем-источника и дальше производить над ними любые манипуляции, не нагружая саму систему источника. Это упрощённый процесс с точки зрения подхода к получению исходных данных: не нужно производить какие-то сложные ETL-процессы преобразования, агрегации. Зато можно хранить сырые данные и получать исторические изменения без необходимости заново получать информацию из источника.
Основным драйвером такого подхода стало появление систем класса MPP — массивно-параллельной обработки и возможность использовать pushdown-оптимизацию (рис. 4). Совмещение этих технологических подходов дало возможность переносить данные из систем-источников в мощное технологическое решение MPP (среди них Teradata, Vertica, Greenplum).
Advanced Architecture реализует концепцию распределённой обработки и возможности горизонтального масштабирования. Такой подход позволяет эффективно преобразовать сырые данные в некие различные слои — как детальные данные, так и витрины, отчёты. При этом таких слоёв может быть несколько. За счёт этого время получения результата сократилось в часы вместо 3-4 дней.
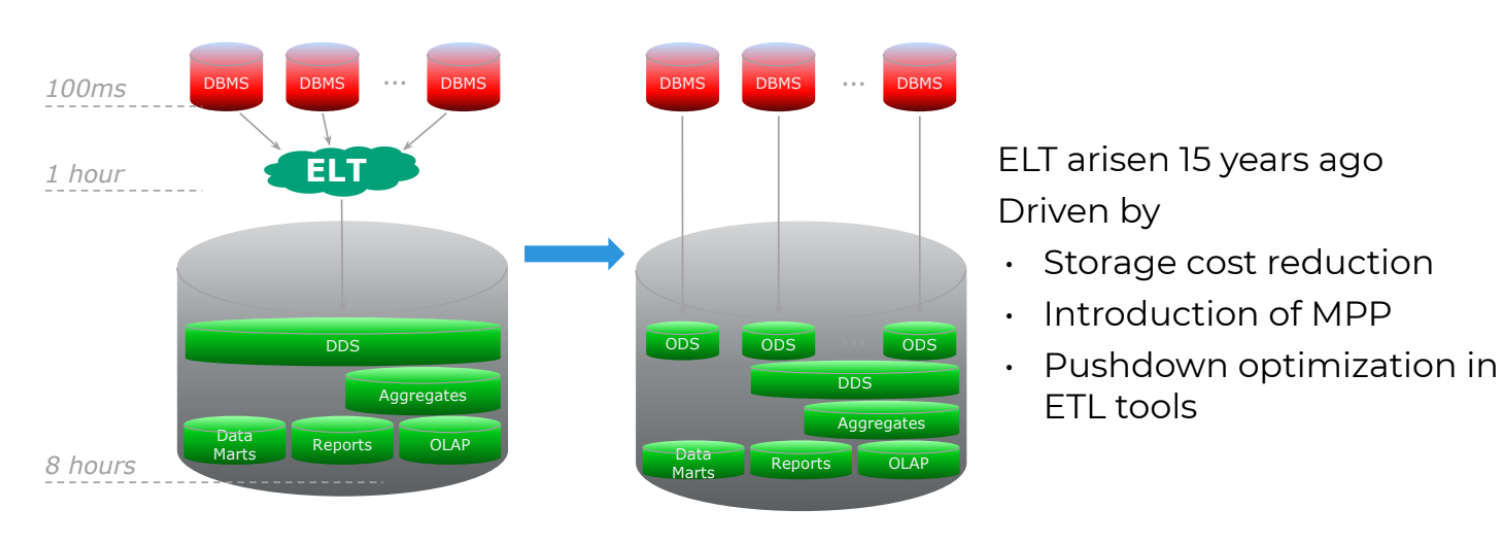
Рис.4
Отставание помог сократить не только ELT-подход, но и CDC (change data capture) — технология, позволяющая воспроизвести изменения систем-источников на удалённом целевом решении, в том числе на уровне MPP-платформ. Здесь существует несколько подходов, но основной из них заключается в том, чтобы использовать так называемые логи или trail-файлы, позволяющие воспроизвести полностью весь цикл изменения исходных данных на системе-источнике и целевой системе.
В результате появляется возможность получить изменение систем-источников, например, в пределах 15 минут. Но это в теории: как правило, процесс занимает чуть больше времени из-за существующей нагрузки на источник. Решить эту проблему помогают механизмы, позволяющие использовать холодные копии исходных данных и воспроизводить именно их. В результате можно сократить отставание до 1-2 часов.
При помощи CDC Advanced Architecture позволила решить проблему и аварийного восстановления (Disaster Recovery). Передача данных обеспечивается различными контурами за счёт воспроизведения изменений на системе-источнике. Это позволяет получить консистентное состояние данных на уровне катастрофоустойчивости с точки зрения отставания в несколько десятков минут.
Основные ограничения. Advanced Architecture не позволяет решать задачи, возникающие в режиме реального времени, потому что оперирует интервалом в десятки минут. Этому препятствует необходимость использовать сторонние инструменты для масштабирования потоков данных, да и сами изменения данных происходят с задержкой.
Пример использования. Advanced Architecture подход стал эволюционным шагом «традиционной архитектуры». К нему привели следующие причины:
- многие существующие компании достигали предела по производительности в части систем хранения и были вынуждены перейти на горизонтально масштабируемую (Scale-Out) архитектуру на базе MPP-систем;
- новые требования к отказоустойчивости и обработке данных потребовали применять более эффективные механизмы обработки и загрузки данных.
Modern Data Architecture
Что это такое. Modern Data Architecture решает задачи, связанные с получением довольно длительной истории основного слоя данных: пользователям становятся доступны сравнения информации в целевой системе за несколько десятков лет (рис. 5). Благодаря этому компания может оперировать большими объёмами данных, что влияет на качество статистической выборки, и, как следствие, растёт точность выдвигаемых гипотез.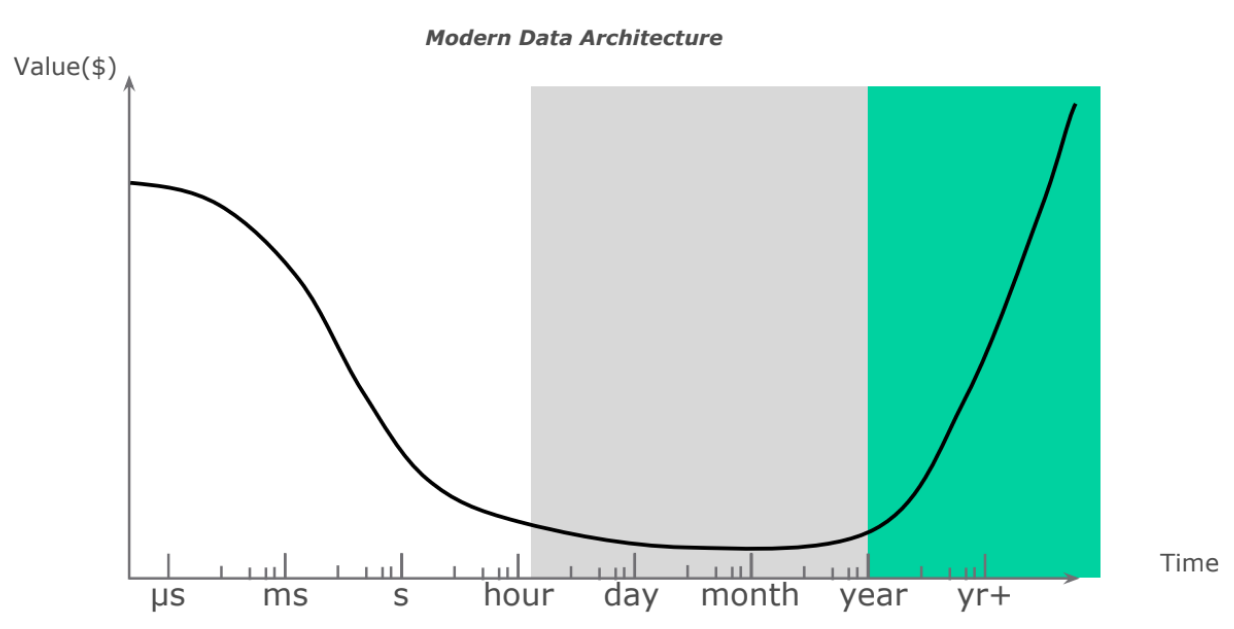
Рис.5
Основным драйвером развития Modern Data Architecture стало появление на рынке такого технологического решения, как Apache Hadoop. Оно позволило в значительной степени снизить ТСО (total cost of ownership) системы за счёт того, что Hadoop изначально является открытым проектом (open source) и разрабатывался для работы на любом повсеместно используемом (commodity) оборудовании.
Здесь же появились механизмы, позволяющие как упростить процесс аварийного восстановления самого решения, так и обеспечить Disaster Recovery различных решений с помощью сторонних средств, входящих в экосистему Apache Hadoop.
Использование Apache Hadoop привело к появлению в подходе к построению современного хранилища данных такого термина, как озеро данных (Data Lake). Его автором стал Джеймс Диксон, один из основателей Pentaho. Идея Data Lake заключается в том, чтобы интегрировать Hadoop-решения в существующие у заказчиков legacy-архитектуры. Благодаря этому можно ускорить процесс подготовки данных, решить вопрос, связанный с хранением большого объёма информации, и гибко использовать широкую экосистему инструментов для эффективного анализа данных.
Modern Data Architecture позволила обрабатывать неструктурированные данные, а также разгрузить дорогостоящие как front-end системы, так и различные DWH-системы.
Как работает. Концепция Modern Data Architecture описана на рисунке 5. Существует DWH-архитектура, которая изначально была построена компанией. В ней протекают свои ELT-процессы. Рядом появляется уровень Hadoop, а вместе их можно назвать Data Lake. На себя Hadoop забирает всю нагрузку с точки зрения долговременного хранения детальных данных, агрегаторов, аналитических архивов, включая данные, попадающие из неструктурированных и слабоструктурированных источников (clickstream, логи). DWH и Hadoop интегрированы между собой набором решений — коннекторами, жизненным циклом данных (процессы, определяющие, какие данные являются востребованными, а какие архивными).
Основное достоинство Modern Data Architecture заключается в том, что компания может получать данные другой структуры, а их отставание от источников сокращается за счёт использования более технологичных и распределённых инструментов обработки. Для эффективной передачи потоковых данных появились стриминг-технологии (Apache Flink, Apache NiFi), которые дали возможность перейти к нативной обработке потока данных в его явном виде. Благодаря им компании смогли решать задачи, ранее недоступные им, при помощи микробатч-процессов обработки данных и строить совершенно новые архитектуры платформ данных.
Основные ограничения. У Modern Data Architecture отсутствует чёткий дизайн с точки зрения имплементации тех или иных решений. А концепция реализации во многом зависит от видения главного инженера проекта.
Более того, бизнес-потребности компании со временем эволюционируют, и задачи, изначально возложенные на хранилище данных, могут меняться. Поэтому время построения каких-то статичных отчётов может увеличиваться с нескольких минут до нескольких часов. Одна из причин: быстрый рост пользователей и бизнес-кейсов, решаемых на Modern Data Architecture и в некоторых случаях не подходящих по нагрузке и сценарию использования данных.
Не до конца решена в Modern Data Architecture и проблема аварийного восстановления, несмотря на имеющиеся в Hadoop специфические инструменты отказоустойчивости.
Ещё одна проблема Modern Data Architecture выходит на сцену, когда Data Lake превращается в Data Swamp — болото данных. Это происходит тогда, когда компании в лавинообразном порядке начинают складывать в Hadoop все данные, которые у них есть. В результате теряется смысл данных, пропадают связи между ними. К счастью, сейчас появился ряд проектов, позволяющих структурировать этот подход и решить вопрос, связанный с построением общей таксономии данных, которые есть в системе. Делается это автоматически. Типичным представителем таких проектов является Apache Atlas.
Многие компании сейчас разрабатывают общую спецификацию построения концепций стратегического управления данными и их качеством. Например, этот вопрос один из первостепенных для некоммерческих организаций, развивающих Open Source, например Open Data Platform Initiative (ODPi).
Пример использования. Data Lake является эволюционным шагом в развитии архитектуры обработки данных. Например, одна европейская телеком-компания смогла снизить текущую нагрузку на инфраструктуру и решить задачу по удержанию клиентов за счёт обработки неструктурированных данных — лог-файлов, где хранилась уникальная информация по обрывам связи. Причём данные загружались и обрабатывались именно за счёт внедрения архитектуры Data Lake. А благодаря появлению новых инструментов был реализован ряд механизмов, позволяющих совершать предиктивные действия по отношению к клиенту.
Lambda Architecture
Что это такое. Lambda Architecture — решение, построенное, в том числе, на Data Lake-концепции, которое позволяет решать задачи, связанные с обработкой в режиме реального времени, обрабатывая данные за миллисекунды. Такой подход к построению хранилища данных даёт возможность работать как с классическим диапазоном (месяцы, часы), так и с историческими данными, которые необходимо хранить в долгосрочной перспективе (рис. 6). Концепцию Lambda Architecture в 2011 году предложил Натан Марц, один из авторов популярного фреймворка Apache Storm.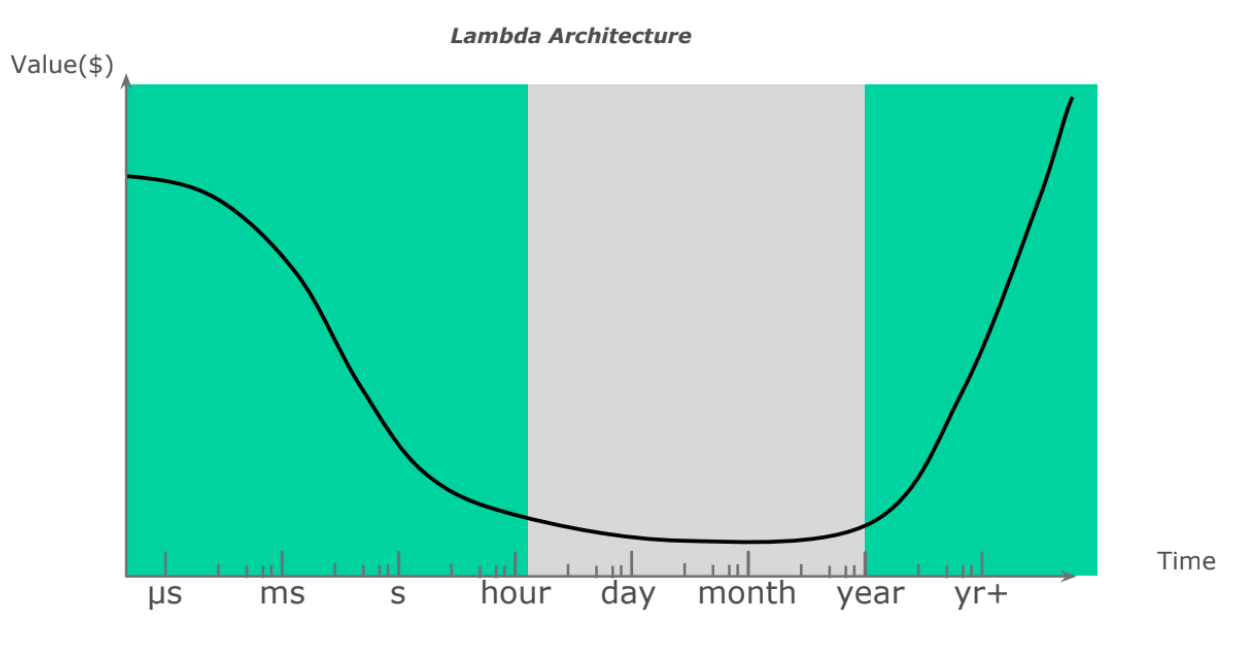
Рис.6
Как работает. Lambda Architecture позволила немного «ослабить» CAP-теорему. Согласно ей ни одна техническая система одновременно не может удовлетворять трём условиям: консистентности, доступности и распределённости. Натан Марц предложил разделить технологические уровни на несколько частей и использовать для них различные технологии, закрывающие со своей стороны два из трёх ограничений CAP-теоремы. Основная идея предполагает существование трёх уровней, позволяющих решать вопросы как real-time обработки (speed layer), где данные появляются в течение миллисекунд, так и исторического слоя (batch layer), когда есть данные, которые нужно хранить в долгосрочной перспективе. Для решения этих задач в платформе хранения данных присутствует федеративный уровень, который может получать оба типа данных и решать задачи разного типа, класса в различных режимах (рис. 7).
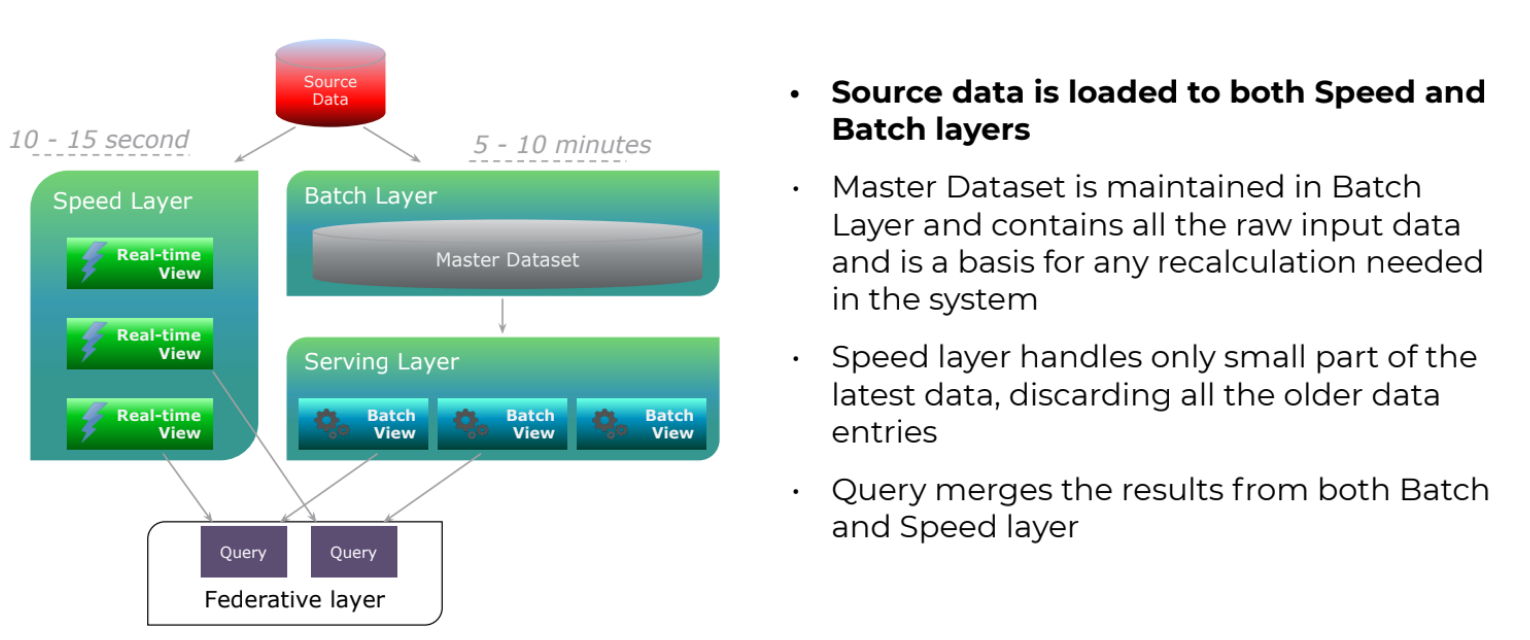
Рис.7
Основные ограничения. Поскольку Lambda Architecture достаточно сложная с точки зрения имплементации, возникает проблема внедрения и эксплуатации таких решений в legacy-инфраструктуры. Однако, в отличие от Modern Data Architecture, существует много информации, включая книгу, которую написал Натан Марц, как реализовать ту или иную часть платформы.
Но остаются вопросы, как перейти на Lambda Architecture с legacy-инфраструктуры. На помощь здесь приходит бимодальное ИТ: рядом с существующей legacy-инфраструктурой строится новая инфраструктура, которая работает для новых проектов. В процессе эксплуатации на новую архитектуру переносятся и критичные для бизнеса задачи.
Второй подход — итеративная имплементация различных дополнительных решений. Этот подход актуален, если изначально путь построения архитектуры подразумевал переход к задачам, связанным с real-time. Например, компания начала с реляционной базы данных с DWH, затем появился Hadoop как озеро данных, на уровне которого в текущую инфраструктуру интегрируются новые инструменты для работы с задачами в режиме реального времени. Так, воспользовавшись вторым подходом, крупная компания смогла в режиме реального времени получать данные с датчиков, установленных на дорожной технике. Анализируя поступающую информацию, бизнес смог сократить расходы на ремонты автомобилей, вовремя внедряя результаты предиктивной аналитики.
Пример использования. Lambda Architecture получила распространение в производственных компаниях и автомобильной индустрии. Некоторые добывающие компании реализовали такой подход для решения задач предиктивного обслуживания и выявления угроз на производстве. На базе исторического слоя собиралась статистика по работе узлов и агрегатов, строились паттерны, позволяющие выявлять потенциальные проблемы. Эти модели работали на уровне speed layer и позволяли в режиме реального времени выявлять ранее смоделированные события.
Data Mesh Architecture
Что это такое. Data Mesh Architecture придумала Жамак Дегани. По её мнению, новый подход поможет компаниям разработать платформу данных третьего поколения, учтя ошибки двух предыдущих (проприетарные хранилища данных и использование Data Lake в качестве серебряной пули). Data Mesh Architecture активно использует стриминг-технологии, объединяет пакетную и потоковую обработки данных, а хранит данные в облаке. Благодаря этому у компаний появляется возможность анализировать данные в режиме реального времени, снизив при этом затраты на управление инфраструктурой хранилища.Как работает. Главное отличие Data Mesh Architecture от предыдущих поколений платформ хранения данных заключается в том, что данные не передаются в Data Lake. Они хранятся и используются командами внутри бизнес-доменов в удобном для них виде. При этом данные в разных доменах могут дублироваться, когда происходит их изменение на удобный конечному пользователю формат.
Естественно, для эффективной работы такой архитектуры необходимо соблюсти ряд условий:
- создать реестр наборов данных с необходимой метаинформацией для того, чтобы их можно было оперативно найти;
- обеспечить каждый набор данных уникальным адресом для получения программного доступа к ним;
- проверять и обеспечивать достоверность и актуальность данных;
- прописывать семантику и синтаксис данных для создания простых в использовании наборов данных;
- разработать правила и стандарты, которые позволят эффективно интегрировать данные между доменами;
- обеспечить безопасный доступ к данным.
Основные ограничения. Чтобы перейти на Data Mesh Architecture, любой компании предстоит пройти большой путь, и речь тут даже не об использовании технологий. Чтобы масштабировать новые принципы, необходимо серьёзно подойти к ведению бизнес-процессов.
Пример использования. Data Mesh Architecture наиболее востребована в компаниях с высокой динамикой роста бизнеса и направлений: среди них крупные ритейлеры, которые или уже перешли на эту архитектуру, или начинают процесс перехода. Это позволит им быстро включать в процесс обработки и подготовки данных новые филиалы и направления бизнеса за счёт возможности масштабирования команд, отвечающих за свою часть данных.
Какой из пяти перечисленных подходов к построению платформы выбрать — решает каждая компания для себя. Однако важно подойти к этому вопросу, вооружившись практическими знаниями. Поэтому, чтобы получить эффективно работающие хранилище, желательно найти партнёра, который имеет большой опыт в успешной реализации подобных проектов.