Будем рады помочь!
Отправьте ваш вопрос через форму ниже, и наши специалисты свяжутся с вами в ближайшее время.

Изначально хранилища Банка были построены
по классике DWH: Subject-oriented, Time-variant, Non-volatile и Integrated. В этой модели были
выделены ключевые сущности: клиенты, счета, договоры и т.д.
Для оркестрации потоков данных использовался Apache Airflow, для загрузки реплик в базы — фреймворк
собственной разработки.
До старта проекта одновременно использовалось
18 локальных аналитических хранилищ, несколько
BI-серверов и «песочниц», а также около сотни разнородных систем-источников.
На этой базе Росбанк развивал «озёро» данных,
где необработанные данные из систем-источников ежедневно загружались в хранилища, преобразовывались
и слой за слоем продвигались до пользовательских витрин.
Преимуществом этого подхода было отсутствие «тяжеловесного» этапа обработки данных перед загрузкой в
хранилище. Это экономило время и обеспечивало постоянную доступность данных. Недостатком — то, что
данные дублировались и были некачественными.
Первоначально, чтобы решить эту проблему, Банк начал загружать «сырые» данные из Hadoop. Однако это
происходило медленно, данные подтягивались не из всех источников и оставались непригодными для
бизнеса.
Сами хранилища при этом занимали много места, никак не переиспользовались, а данные из множества
источников излишне перегружали системы. Содержали и обслуживали разные хранилища разные команды, что
обходилось Банку в сотни млн рублей.

«Мы приняли решение, что нам нужно создать единую data-платформу, которая сможет своевременно обеспечивать бизнес необходимыми данными, подготовленными в соответствии с принятой в банке моделью. В качестве целевых систем для построения нового КХД мы выбрали Greenplum и Hadoop».
На первом этапе были выбраны системы и технологии для создания единого КХД, а также развёрнута
инфраструктура для нового хранилища.
К новому хранилищу было подключено свыше 50 систем-источников. Было обеспечено ежедневное обновление
и круглосуточный мониторинг доступности данных.
Также были разработаны единые стандарты для масштабирования команды разработки,
автоматизированы CI/CD-поставки нового функционала и настроены потоки данных по слоям в рамках новой
корпоративной модели:
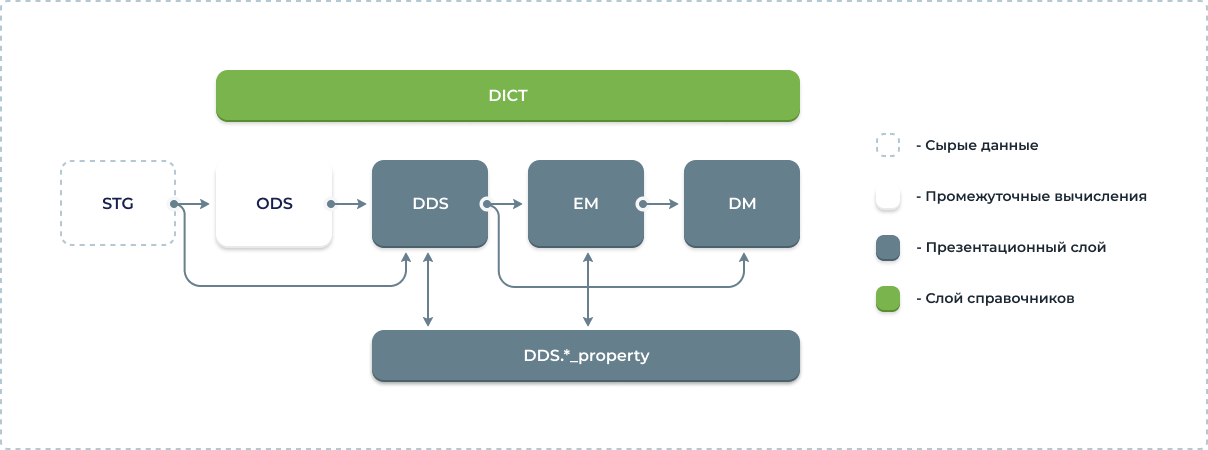
Первый слой — STG. В нём хранятся «сырые» данные, которые поступают в Hadoop (изначально был дистрибутив Hortonworks, с которого прошла миграция на Arenadata Hyperwave).
Второй слой — ODS.Это слой для накопления истории из слоя STG по нужным атрибутам.
Третий слой — DDS. Он содержит детальные данные по основным сущностям (клиенты, счета, договоры, проводки, балансы и тому подобное).
Четвёртый слой — EM.Представляет собой витрины с агрегированными показателями базовых сущностей: клиентский портфель, портфель HR, кредитные и депозитные портфели и так далее.
Пятый слой — DM. Это витрины данных Банка с рассчитанными агрегатами для всех департаментов организации. На его основе формируются отчёты. У него есть также дополнительные специализированные витрины для отдельных задач бизнеса.
Шестой слой — DIC. Слой справочников, которые можно загружать вручную, наполняя из файлов, подтягивая из систем-источников: MDS, API и так далее

Банк проанализировал функциональные
и нефункциональные требований к аналитической СУБД и пришёл к выводу, что для OLAP нужна
массово-параллельная система, способная обрабатывать
не менее 100 Tб. В числе обязательных критериев
также были отказоустойчивость, совместимость
с Hadoop, высокая скорость обработки OLAP-запросов, умеренная стоимость и возможность
подключения множества источников.
Рассмотрев доступные на тот момент решения (Vertica, Oracle Exadata, IBM DB2, «ванильный»
Greenplum), по совокупному набору критериев Росбанк выбрал Arenadata DB.

«В качестве наиболее очевидных плюсов миграции на Arenadata DB можно отметить ещё и то, что у нас появилась возможность одновременного поддерживать старое хранилище и переносить функционал в новое. Мы сократили затраты на лицензии и „железо“, стали тратить меньше времени на аналитику, и все данные у нас теперь аккумулируются в одном хранилище. Сложности, связанные с ограниченными знаниями команды продуктов Arenadata, мы решили с помощью обучения на вендорских курсах Arenadata и создания внутренней data-школы».

Изменениями в рамках проекта были охвачены свыше 2 тысяч сотрудников из разных подразделений Банка. В итоге были достигнуты следующие результаты:
В эксплуатацию введено единое хранилище Банка с общей корпоративной моделью данных
Проведена «бесшовная» миграция локальных хранилищ (бизнес не заметил технического перехода).
Сотрудники получили новые компетенции и навыки.
Банк сократил расходы на OLAP.
Были подтверждены выбранные технологии и модели.
Решена задача импортозамещения.
Отправьте ваш вопрос через форму ниже, и наши специалисты свяжутся с вами в ближайшее время.