
Второй крайне важный фактор — общая специфика использования. Тут можно выделить две основные группы — OLTP (транзакционные системы) и OLAP (аналитические системы):
- OLTP (Online Transaction Processing) — системы, ориентированные на выполнение большого числа коротких транзакций: вставки, обновления и удаления отдельных записей. Они обеспечивают быстрый отклик и надёжную работу с операционными данными, характерными для интернет-магазинов, банковских приложений, биллинговых и ERP-систем.
- OLAP (Online Analytical Processing) — системы для выполнения сложных аналитических запросов: агрегирования по большим наборам данных, многоступенчатые JOIN’ы, оконные функции, CTE/подзапросы, сложные группировки и фильтры. Подходят для проверки аналитических гипотез, построения отчётности и витрин; оптимизированы под параллельную обработку и сканирование крупных таблиц.
Сейчас необходимости поддержки масштабирования и решения аналитических задач всё чаще пересекаются. Возникает потребность в аналитических MPP-СУБД для OLAP. Одна из таких баз данных — Greenplum/Greengage.
Greengage — это свободно распространяемая система управления базами данных (СУБД) под лицензией Apache License 2.0 (ASF 2.0), которая будет развиваться как самостоятельный открытый продукт, изначально реализованный на технологии Greenplum.
Это проверенная open source технология, имеющая многолетний опыт эксплуатации в крупнейших российских и зарубежных компаниях.
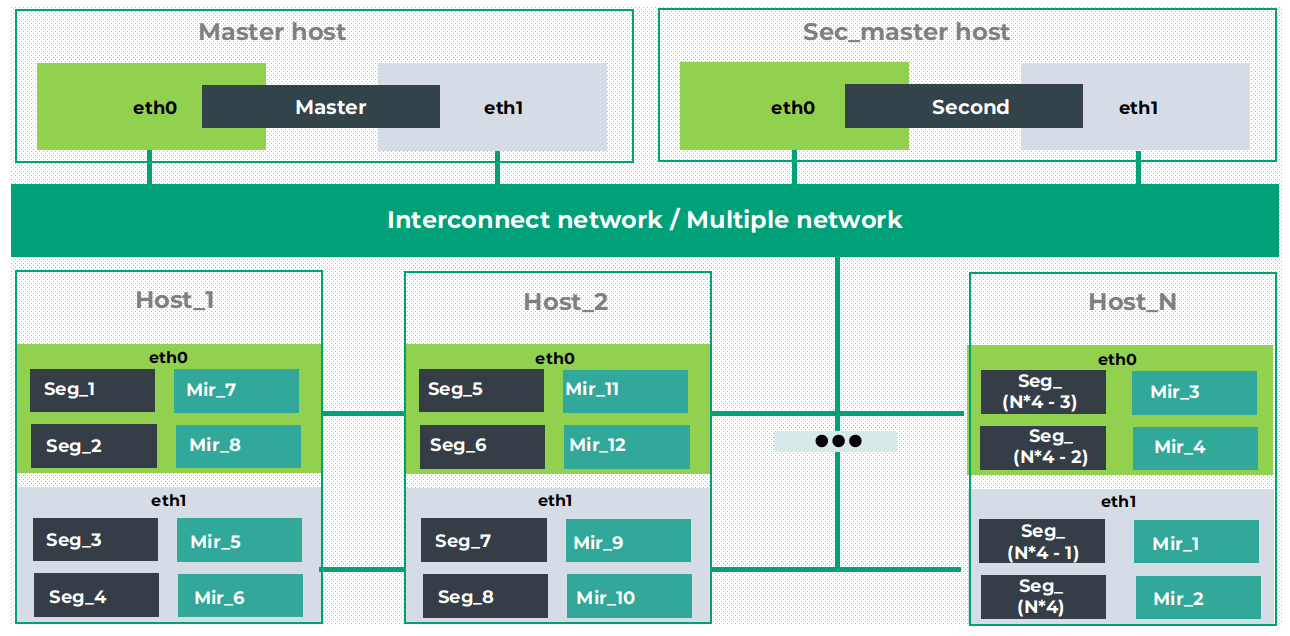
Система изначально обладает встроенной отказоустойчивостью: предусмотрено зеркалирование как мастер-хоста, так и отдельных сегментов. Greenplum/Greengage — это массивно-параллельная (MPP) распределённая система с «честной» моделью shared nothing. Кластер состоит из нескольких связанных экземпляров PostgreSQL, которые совместно обеспечивают хранение и обработку данных.
Основные компоненты:
- Мастер-сервер (Master host) — принимает SQL-запросы от клиентов, координирует выполнение и агрегирует результаты.
- Резервный мастер (Standby master) — обеспечивает отказоустойчивость: содержит актуальную копию данных основного мастера и может быть активирован в случае сбоя основного мастера.
- Узлы-сегменты (Segment hosts) — здесь хранятся и обрабатываются данные. Каждый сегмент — это отдельный экземпляр PostgreSQL, который хранит часть общего объёма данных. Сегменты делятся на основные (primary) и зеркальные (mirror), что обеспечивает репликацию и отказоустойчивость на уровне отдельных узлов.
Ещё одна сильная сторона Greenplum/Greengage — хорошая совместимость с PostgreSQL. Это означает, что система поддерживает реляционную модель данных и привычный синтаксис SQL, благодаря чему она интегрируется со всеми BI- и ETL-инструментами
Когда применять Greenplum/Greengage
Как мы уже обсудили выше, Greenplum/Greengage имеет смысл применять, когда нам нужна горизонтально масштабируемая аналитическая СУБД или основа для реализации надёжного и безопасного корпоративного хранилища данных (КХД). Добавим немного конкретики и рассмотрим случаи, когда стоит задуматься о Greenplum/Greengage:
- Вам нужно изначально иметь хранилище не менее 3 ТБ, а также явные тенденции к росту объёма данных.
- OLAP-нагрузка — выполнение сложных аналитических запросов с агрегацией, оконными функциями и соединением больших таблиц.
- Внедрение объектов КИИ — использование в проектах критической информационной инфраструктуры, где требуются повышенные меры защиты (ФСТЭК, регуляторные требования, строгие политики безопасности).
- Системы регулярной отчётности (управленческой, операционной, МСФО и т. д.).
- Предиктивный анализ — анализ текущих и прошлых данных или событий для прогноза будущих данных или событий. Например, в директ-маркетинге, целевой рекламе, управлении инвестиционными рисками, выявлении мошеннических схем.
- Ad-hoc-аналитика — сегментация рынка, концепция продукта, эффективность рекламы, потенциал компании или бренда, каналы сбыта, эффективность продаж.
- Маркетинговый анализ — целевая аудитория, конкуренты, ценовые предложения.
- Финансовый скоринг — оценка кредитоспособности заёмщиков, оценка наиболее вероятных финансовых действий и др.
- Анализ клиентской базы — АВС-анализ (сегментация по объёму продаж и прибыли), XYZ-анализ (сегментация по частоте покупок или сделок).
- Анализ данных логистики — сроки доставки, затраты на перевозку, расходы на хранение груза.
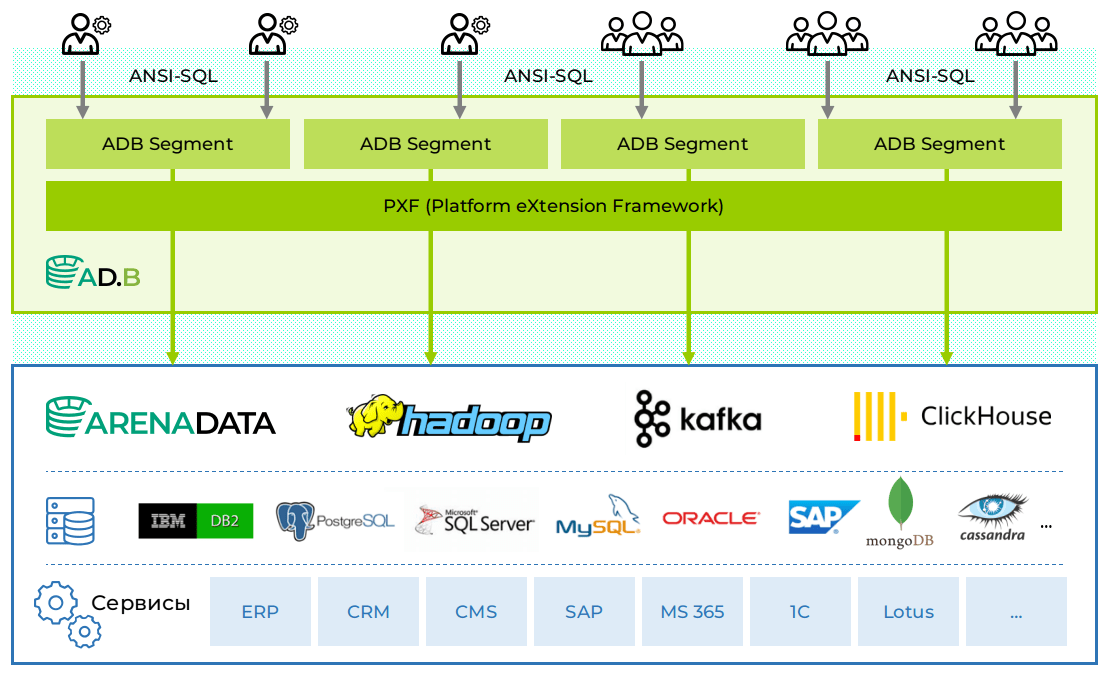
Ещё одно преимущество Greenplum/Greengage — фреймворк PXF (Platform Extension Framework), который обеспечивает параллельный высокопроизводительный доступ к разнородным источникам данных. Для его подключения необходимо установить специальный сервис на хосте с сегментами. Он с одной стороны общается с ними по проприетарному протоколу, а с другой имеет стандартизованный Java API, который позволяет подгружать плагины для параллельного обмена данными с внешними системами. «Из коробки» доступны распределённая файловая система HDFS, СУБД Apache Hive и Apache HBase, s3 и JDBC-подключения. Если надо работать с другими сервисами — довольно легко реализовать собственные плагины.
Внутри Greenplum/Greengage можно использовать разные типы локальных носителей: размещать наиболее востребованные данные на SSD для быстрого доступа, а менее критичные — на HDD для оптимизации стоимости хранения.
СУБД Greenplum/Greengage можно гибко дополнить сервисами из экосистемы Hadoop или продукта Arenadata Hyperwave (ADH). Такая архитектура позволяет переносить архивные или объёмные данные, которые не нужны в постоянном доступе, во внешние хранилища — например, в HDFS или Ozone, — сохраняя возможность работать с ними через сервисы экосистемы Hadoop или Arenadata Hyperwave (ADH).
Greenplum 7
С выходом Greenplum 7 система получила не только современную кодовую базу PostgreSQL 12, но и целый набор долгожданных улучшений.
Среди ключевых изменений:
- Интерфейс табличных методов доступа (Access Methods)
В Greenplum 7 произошёл рефакторинг встроенных форматов хранения на реализованный в PostgreSQL 12 интерфейс табличных методов Access Methods. Это позволило упростить поддержку различных форматов хранения и развивать AO-таблицы независимо от heap. - Уникальные индексы для AO-таблиц
Теперь AO-таблицы поддерживают уникальные индексы. Для этого интерфейс табличных методов доступа был расширен функциями. - INSERT ON CONFLICT (UPSERT)
Поддержан для heap-таблиц. AO-таблицы пока не поддерживают спекулятивные вставки и конкурентные обновления, поэтому UPSERT на них недоступен. - Функционал покрывающих индексов
Выполнена доработка, позволяющая проверять видимость строк без обращения к heap- и AO-таблицам. Это позволяет оптимизировать время выполнения запросов в ряде сценариев. - Добавление колонок без перезаписи таблицы
Теперь можно добавлять столбцы с DEFAULT-значением без полной перезаписи таблицы. Реализовано как для heap-, так и для AO-таблиц (с рядом технических особенностей). - BRIN-индексы
Добавлена поддержка BRIN-индексов — компактных и эффективных при выборке диапазонов значений. Для AO-таблиц была реализована собственная логика разбивки блоков и хранения метаинформации. - Расширение возможностей FDW (Foreign Tables)
Добавлена поддержка pushdown-соединений, сортировок и агрегатов во внешние источники. Это снижает нагрузку на кластер, позволяет уменьшить объём данных, передаваемых между системами, и улучшить производительность запросов. - Улучшенный мониторинг рабочих процессов
Добавлены расширенные wait-events и представление gp_stat_activity, отображающее состояние всех процессов по всему кластеру. - Современное партиционирование
Полный переход на нативное партиционирование PostgreSQL. Удалены старые представления (pg_partitions и др.). Поддержан postgres-синтаксис и функции, включая HASH и неоднородное партиционирование. - Row Level Security
Реализована фильтрация строк по политике безопасности. - Разрешения по умолчанию (Default Privileges)
Можно задавать права на объекты, которые будут создаваться в будущем в схемах или ролями — важное улучшение для администрирования доступа. - WAL удерживаются только для последней контрольной точки
Снижено потребление диска за счёт отказа от хранения WAL для двух последних контрольных точек — осталось только для последней. - Just-in-Time-компиляция (JIT)
Добавлена JIT-компиляция выражений, что повышает производительность при выполнении тяжёлых аналитических запросов. Работает и с ORCA. - Генерируемые столбцы (Generated Columns)
Поддержаны хранимые (stored) вычисляемые поля, которые рассчитываются из других атрибутов строки. Не могут использоваться как ключ распределения. - SQL/JSON Path
Добавлена поддержка языка JSON path — теперь можно выполнять более гибкие запросы к данным внутри JSON. - Autoanalyze для пользовательских таблиц
Введён автоматический сбор статистики после DML-операций на координаторе. - Оптимизация ANALYZE для AO-таблиц
ANALYZE теперь использует каталоги блоков (если есть индекс) для выборки строк, не сканируя AO-таблицу целиком, а также использует логические блоки, исключая затраты на декомпрессию всей таблицы. Это позволило ускорить процесс в 20 раз. - Обновлённая работа внешних таблиц
CREATE EXTERNAL TABLE теперь реализован через FDW API. Работа с внешними источниками — через gp_exttable_server, но синтаксис сохранён. - Resource Groups: переработка лимитов
Появилась поддержка cgroup v2, добавлены ограничения на IO (MB/s, IOPS), переработана логика лимитов по CPU и памяти. Появилась системная группа system_group.
Greenplum 7 существенно расширяет возможности распределённой аналитики. Это не просто очередной апгрейд, а системное обновление SQL-движка, призванное повысить скорость и эффективность обработки петабайтов данных, при этом сохраняя совместимость с PostgreSQL. Именно эта версия сегодня становится технологической базой для развития Arenadata DB 7 и проекта Greengage 7.
Что произошло с Greenplum: закрытие исходников и будущее пользователей
В 2024 году сообщество Greenplum столкнулось с неожиданным изменением курса: компания Broadcom, ставшая новым владельцем VMware Tanzu и связанных с ним продуктов, в том числе Greenplum, закрыла публичный доступ к исходному коду системы и полностью сосредоточилась на развитии коммерческой версии 7.x. Это означало не только прекращение open source подхода, но и утрату каналов коммуникации между разработчиками, сообществом и бизнесом: больше невозможно вносить вклад в развитие проекта, обсуждать будущие фичи и влиять на его стратегию.
В результате пользователи «ванильного» Greenplum оказались в подвешенном состоянии. Перед ними встал выбор: остаться на устаревающей версии без гарантий обновлений и безопасности, полностью перейти на закрытую коммерческую ветку Broadcom либо искать полноценную open source альтернативу с долгосрочной поддержкой и прозрачным развитием.
Открытый форк Greenplum под управлением Arenadata
С целью сохранить принципы открытой разработки и обеспечить стабильную платформу для существующих и новых пользователей компания Arenadata запустила независимый проект Greengage — полнофункциональный форк Greenplum 6/7, распространяемый под лицензией Apache 2.0. Он сохраняет совместимость с Greenplum и обеспечивает бесшовный переход для тех, кто ранее использовал оригинальную систему.
В феврале 2025 года команда Greengage выпустила первые стабильные релизы: версии 6.28 и 7.3, полностью совместимые с соответствующими релизами Greenplum. При этом Greengage развивается не просто как форк для сохранения функционала, а как самостоятельный open source проект — с открытой дорожной картой, публичными репозиториями и документацией.
Greengage стал фундаментом для дальнейшего развития коммерческих продуктов ADB 6 и ADB 7. Проект развивается в направлении расширения функционала Greenplum, повышения уровня его безопасности, улучшения стабильности и интеграции с современными инструментами аналитики и хранения данных.
Как помочь проекту? (после коммуникации в сообществе от разработки)
Если вы хотите помочь развитию Greengage, у вас есть несколько простых способов это сделать. Подписывайтесь на официальные каналы проекта, следите за обновлениями в соцсетях, телеграм-канале и на GitHub. Мы регулярно публикуем новости, рассказываем о новых возможностях и делимся планами по развитию. Любая обратная связь, идеи и багрепорты от пользователей помогают делать Greengage лучше. Присоединяйтесь к комьюнити — вместе мы создаём надёжную open source платформу для аналитических задач.
Arenadata DB (ADB): российское решение на базе Greenplum
Как мы помним, Greenplum/Greengage является open source проектом. В его доработке могут участвовать разработчики со всего мира. В 2019 году второе место в мире по числу коммитов заняла российская компания Arenadata. Наша компания опередила в числе прочего и китайского гиганта Alibaba Group. С 2018 года компания развивает собственную MPP-СУБД на базе Greenplum — Arenadata DB. Это оптимальное решение для создания надёжных хранилищ данных с высокой скоростью обработки аналитических запросов любой сложности. Эта защищённая и гибко масштабируемая СУБД обеспечивает непрерывность критичных бизнес-процессов и возможность неограниченного роста компании. ADB включает встроенный инструмент установки и управления кластером (ADCM), систему мониторинга и алертинга, поддержку отказоустойчивости, двусторонние коннекторы к Kafka, ClickHouse, Spark, а также контроль за использованием ресурсов на уровне запросов и пользователей.
При этом начать можно с бесплатной community-версии ADB: она основана на актуальном ядре Greengage, устанавливается за 15–30 минут, не требует сложной настройки и отлично подходит для лабораторий, PoC, пилотов или интеграционных тестов. Когда проект «вырастает» — миграция на enterprise-редакцию с поддержкой, обновлениями, дополнительным функционалом и SLA возможна поверх уже установленной community-версии.
Как развернуть ADB буквально за полчаса — читайте в нашей статье (ссылка на статью по установке ADB)
Arenadata DB имеет ряд преимуществ перед «ванильным» Greenplum:
- Arenadata Cluster Manager — инструмент, значительно упрощающий установку и настройку СУБД, в том числе в закрытых ЦОДах без доступа в интернет.
- Нативная интеграция с Arenadata Hyperwave (ADH), Arenadata QuickMarts (ADQM) ClickHouse, Arenadata Streaming (ADS) Kafka&NiFi в рамках единой платформы Arenadata EDP и другие дополнительные возможности интеграции.
- Система мониторинга и оповещения.
- Arenadata DB Control (ADB Control) — это система мониторинга запросов Arenadata DB в режиме реального времени.
- Arenadata DB Backup Manager (ADBM) — отказоустойчивая система управления бинарными бэкапами ADB, построенная на основе pgBackRest. Поддерживает гибкую настройку политик резервного копирования, создание точек восстановления (restore points), ведение истории бэкапов, работу с несколькими кластерами и интеграцию с S3- и POSIX-совместимыми хранилищами.
Отдельно стоит отметить преимущества для заказчиков, работающих в России: наличие русскоязычной документации, возможность развёртывания в отечественных облачных решениях, в том числе по модели PaaS, обучающие курсы и вебинары, техподдержка 24/7. Важнейший аспект — соответствие требованиям регуляторов и наличие сертификации ФСТЭК (по 4-му и 6-му уровню доверия), что делает Arenadata DB применимой в проектах с повышенными требованиями к безопасности и надёжности.
Подробное сравнение возможностей редакций Greenplum смотрите в таблице ниже:
| Функционал | Open Source* (Закрыт в мае 2024) |
ADB Community Edition | ADB Enterprise Edition |
|---|---|---|---|
| Core-функционал | + | + | + |
| PXF | + | + | + |
| gpbackup | + | + | + |
| Коннекторы Greenplum <-> Hadoop и Greenplum <-> JDBC-источники | + | + | + |
| Коннекторы Greenplum <-> Kafka и Greenplum -> ClickHouse | — | — | + |
| ADB Control (мониторинг на уровне запросов) | — | — | + |
| Офлайн-установка | — | — | + |
| Управление деплоем и апгрейдом | — | + | + |
| Расширение кластера | — | + | + |
| Мониторинг & алертинг | — | + | + |
| Инструментарий управления бэкапами (ADBM) | — | — | + |
| Бинарные инкрементальные бэкапы (WAL binary Backup / Restore) | — | — | + |
| Документация (английский, русский) | English only | + | + |
| Техническая поддержка | — | — | + |
| Обучение по продуктам | — | — | + |
| Операционные системы | Ubuntu 18.04 Redhat 7 Redhat 6 |
CentOS 7 Redhat 7 Ubuntu 22.04 LTS |
CentOS 7 Redhat 7 Ubuntu 22.04 LTS Альт 8 СП Альт СП релиз 10 Astra Linux 1.7 SE “Орел” Astra Linux 1.7 SE “Воронеж” РЕД ОС 7.3 (сертифицированный) |
| Консалтинговые услуги | — | — | + |
Кейсы использования Greenplum /Greengage / Arenadata DB от российских компаний
Решения на базе Arenadata DB, построенной на Greenplum/Greengage, занимают устойчивые позиции в ритейле и финансовой сфере. Система помогает им быстро трансформироваться в цифровые компании, уменьшить срок time-to-market для своих продуктов и идей. Благодаря продукту ADB ритейлеры и банки узнают больше о своих клиентах, лучше предсказывают их поведение, получают возможность точнее предлагать товары или банковские услуги, сокращать накладные расходы на логистику.
Система становится всё более востребованной в сферах бизнеса, где необходимо хранить и обрабатывать большие объёмы данных. Среди них логистика, IoT, производство, агропромышленность, системы безопасности, ЖКХ.
Ритейл
«Комус». Крупнейшая российская торговая компания, работающая в сегменте B2B-товаров, начала использовать российскую аналитическую СУБД Arenadata DB в облачной платформе VK Cloud. Переход на российское ПО позволит снизить затраты, ускорить массивно-параллельные вычисления, получить современные средства аналитики и сократить время принятия бизнес-решений. Выбор облачной версии Arenadata DB также положительно скажется на показателе time-to-market. Предполагается, что модель данных в новом хранилище будет максимально приближена к существующей, а работа бизнес-пользователей в текущих системах BI не будет нарушена.
«Вкусно — и точка». Всего за один год на базе продуктов Группы Arenadata создана централизованная платформа данных, включающая хранилище данных, BI-систему, ML-модели, MDM, средства ETL, каталог данных, систему self-service-аналитики и интеграционную шину для обмена данными. Платформа данных была построена на базе продуктов Группы Arenadata, специально подобранных под задачи клиента. В качестве ядра хранилища больших данных использована СУБД Arenadata DB (ADB), для высокопроизводительной аналитики — Arenadata QuickMarts (ADQM), для потоковой обработки данных в режиме реального времени — Arenadata Streaming (ADS), а для управления метаданными — Arenadata Catalog (ADC).
Телекоммуникационные компании
«МегаФон». Приступил к работам по миграции своей аналитической платформы на отечественное программное обеспечение. Внедрение позволит «МегаФону» решать весь комплекс бизнес-задач по развитию корпоративного хранилища данных (КХД) с использованием исключительно российских решений. Базовым компонентом КХД станет Arenadata DB, предназначенная для развития и эксплуатации среди прочего задач клиентской аналитики, подготовки финансовой, управленческой и регуляторной отчётности, а также подготовки данных и анализа результатов маркетинговых кампаний. Arenadata DB обеспечивает сбор, трансформацию и интерпретацию данных, поступающих из более чем сотни систем-источников, в том числе биллинговых систем «МегаФона».
Финансовый сектор
Московская биржа. Продукты Arenadata будут использованы для развития единого хранилища данных Московской биржи. В основу его архитектуры ляжет СУБД Arenadata DB (ADB). С начала сотрудничества Московская биржа и Arenadata успешно провели ряд пилотных проектов, призванных подтвердить применимость выбранной технологии для построения хранилища данных. Особое внимание уделялось соответствию требованиям безопасности, надёжности и производительности системы.
ПСБ. Банк ПСБ в рамках стратегического развития реализует проект по созданию Единого хранилища данных (ЕХД) и платформы Big Data, одним из ключевых технологических компонентов которого стала распределённая СУБД Arenadata DB (ADB) от российского вендора Arenadata. Уже сегодня проводимые в его рамках работы позволили улучшить качество клиентских данных физических лиц на 56,1%. Специалисты ПСБ сравнивали производительность Arenadata DB и других СУБД, уже используемых в банке для аналогичных задач. По итогам тестирования Arenadata DB показала наивысшую производительность работы. Кроме того, на момент проведения тестирования Arenadata DB была единственным ПО, включённым в Единый реестр российского программного обеспечения для электронных вычислительных машин и баз данных (ЕРРП) Минцифры РФ и подходящим для задач построения аналитических хранилищ данных.
Россельхозбанк (РСХБ). В 2025 году банк организовал централизованную платформу для бизнес-аналитиков на базе продукта Arenadata DB (ADB). В результате его внедрения удалось отказаться от разрозненных сред обработки данных, ускорить загрузку и повысить прозрачность процессов. За координацию проекта отвечал Департамент больших данных РСХБ, в проекте участвовала компания «РСХБ-Интех», входящая в структуру банка. В качестве технологической базы выбран продукт Arenadata DB. Оркестрация процессов загрузки реализована с помощью Airflow, для работы с ML-инструментами используется ИИ-платформа RAISA (RSHB AI Systems and Applications), а для визуализации данных используется отечественная BI-платформа. Благодаря MPP-архитектуре Arenadata DB удалось ускорить выполнение ETL-процессов и повысить отказоустойчивость. Комплексный подход позволил упростить архитектуру, повысить прозрачность процессов и обеспечить соответствие требованиям импортозамещения.
Промышленность
«Норникель». Лидер горно-металлургической промышленности в России и мире построил технологичную платформу для решения бизнес-задач с применением Big Data и Data Lake на продуктах отечественного вендора Arenadata. Использование «озера данных» позволяет «Норникелю» сократить время time-to-market реализации цифровых проектов за счёт отсутствия необходимости проектировать и реализовывать интеграционные инструменты, а также существенно снизить аналитическую нагрузку на системы управления и диспетчеризации производства. Единой точкой доступа к данным и одним из основных компонентов платформы является аналитическая СУБД Arenadata DB (ADB). Помимо этого, в «озере данных» используется продукт для потоковой обработки данных Arenadata Streaming (ADS) и корпоративный дистрибутив для распределённой масштабируемой обработки данных Arenadata Hyperwave (ADH).
«АЛРОСА». Алмазодобывающая компания внедряет новую информационную систему по управлению данными, которая станет фундаментом для построения различных аналитических систем: отчётности, бюджетирования, консолидации и машинного обучения. Её основой стали продукты российского вендора Arenadata — Arenadata DB, Arenadata Hadoop и Arenadata QuickMarts (ADQM).
Как стать специалистом по Greenplum/Greengage и Arenadata DB
Центр обучения Arenadata предлагает актуальную линейку обучающих программ: краткие, практико-ориентированные курсы с лабораторными работами, которые выполняются в удалённом стенде — достаточно браузера и VPN-доступа. Ниже — выжимка самых востребованных треков на текущий момент.
«Введение в ADB/Greenplum» — однодневный практический курс по работе с Greenplum/ADB. В его рамках участники получат теоретические знания и практический опыт:
- по архитектуре решения Greenplum/ADB (включая подключение и обзор системы);
- концепции простых и партиционированных таблиц и особенностям их реализации в Greenplum;
- работе с планами запросов и статистикой;
- особенностям многопользовательской работы в Greenplum (транзакции и блокировки);
- реализации хранимых функций.
«Arenadata DB для аналитиков» — 2-дневный курс для аналитиков и профильных специалистов, которые планируют научиться использовать ADB для задач обмена и анализа данных. Он даёт необходимые знания для эффективной и безопасной эксплуатации ADB в продуктовых средах, развёртывания схем и таблиц, написания процедур, оптимизации запросов, интеграции с другими системами. Освоение каждой практической темы подкрепляется лабораторной работой.
«Эксплуатация Arenadata DB» — 5-дневный курс для системных администраторов, архитекторов, разработчиков, аналитиков, использующих Arenadata DB. Он даёт необходимые знания для эффективной и безопасной эксплуатации ADB в продуктовых средах, загрузки, обработки и выгрузки данных, настроек безопасности и дополнительных расширений. Освоение каждой практической темы подкрепляется лабораторной работой.
«Arenadata DB для разработчиков» — интенсивный 5-дневный курс, который даёт необходимые знания для эффективной и безопасной эксплуатации ADB в продуктовых средах, развёртывания схем и таблиц, написания процедур, постройки витрин, загрузки, обработки и выгрузки данных, настройки безопасности и дополнительных расширений, позволяет решать проблемы с производительностью и другие часто возникающие ошибки.
Эта статья носит ознакомительный характер. Наиболее полную актуальную информацию по установке, настройке и техническим возможностям наших продуктов можно найти на сайте с документацией: https://docs.arenadata.io.