
Как мы переписали планировщик слияний в Vinyl: от shape-based к интеллектуальному compaction
В предыдущей статье о Vinyl я рассказывал об архитектуре LSM-движка Tarantool. Восемь лет, прошедшие с момента написания статьи, показали, что Vinyl сразу получился идеальным и менять его не нужно :). Если серьёзно, сегодня я расскажу о тех изменениях, которые мы внесли в алгоритм в форке Tarantool от Picodata, и неизбежно коснусь более глубокой проблематики работы LSM-деревьев, а конкретнее — работы планировщика слияний (compaction scheduler).
Начну с базы, а именно с того, как устроено LSM-дерево. Затем расскажу об особенностях Vinyl и напомню его ключевые отличия от классических LSM движков. Потом поговорим про задачи compaction scheduler, опять же, разберём то, что делает текущий Vinyl, какие с этим есть проблемы и как эти проблемы можно решить. А завершим описанием ключевых изменений, уже доступных в Tarantool 2.11.8 от Picodata и в Picodata 26.1.
Основная идея LSM — амортизация стоимости вставок за счёт более высокой стоимости чтений. При вставке данные не попадают немедленно в свою целевую локацию во внешней памяти (на SSD), а кэшируются в оперативной памяти. При переполнении кэша он вытесняется на диск, а после нескольких вытеснений данные из всех вытесненных файлов сортируются и сливаются в новый общий файл, где изменения по одному и тому же ключу объединяются. Такой подход фактически меняет субъект хранения — вместо того, чтобы хранить строки, LSM-деревья хранят и упорядочивают изменения строк. При чтении все изменения собираются воедино для получения итогового результата.
Подход получил широкое распространение с переходом на SSD диски, где чтение в разы дешевле, чем запись, но в целом отлично себя проявляет и с SATA дисками за счёт снижения рандомизированного ввода-вывода. Подробнее об устройстве Vinyl в моей предыдущей статье.
Compaction vs VACUUM
Подход с версионированием изменений не уникален для LSM. Похожим образом MVCC движки, например PostgreSQL, управляют множеством версий данных, порождаемых транзакциями. Но между VACUUM в B-tree и слиянием в LSM есть принципиальная разница.
В B-tree стоимость операции предсказуема. Вставка строки — это O(log N) обращений к диску плюс-минус split страницы. VACUUM работает асинхронно и не влияет на стоимость транзакции. Да, если VACUUM не успевает, таблица “раздувается” (table bloat) — но каждая отдельная транзакция по-прежнему стоит O(log N).
В LSM-дереве такой гарантии нет. Вставка строки в L0 (верхний уровень, in-memory) — O(1). Но если L0 переполняется, запускается дамп (сброс на диск). Дамп может переполнить L1, что вызовет слияние L1 с L2. Слияние L1 с L2 может переполнить L2, что вызовет слияние L2 с L3 — и так далее, каскадом, вплоть до полного слияния всех уровней (major compaction). Одна вставка может спровоцировать перезапись всех данных на диске.
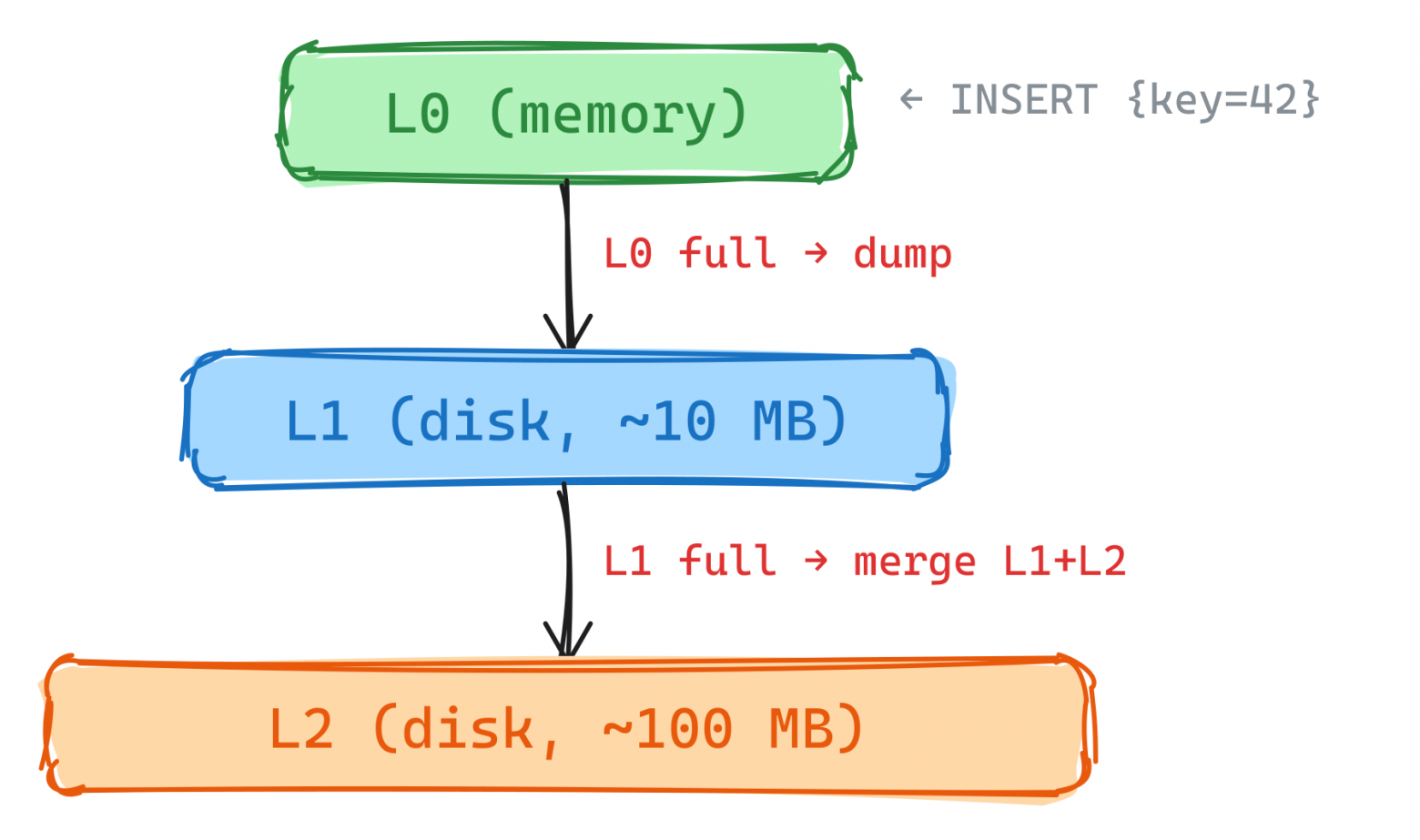
Нет гарантии и стоимости чтения. Представьте, что вы в бесконечном цикле читаете короткий диапазон ключей из таблицы и обновляете прочитанные значения. Для чтения диапазона нужно слить данные со всех уровней LSM дерева, но обновления немедленно не отражаются на данных на диске — соответственно при последующих итерациях цикла вам вернутся неактуальные версии строк, которые нужно пропустить, и чем больше обновлений вы сделали, тем больше мусора нужно отфильтровать, и так до тех пор пока не произойдёт compaction.
Третий пример плохой работы базового алгоритма — time series data, то есть данные временных рядов. Такие данные заведомо упорядочены, но базовый алгоритм будет переупорядочивать их снова и снова при прохождении по уровням LSM дерева.
Read, write и space amplification
Apache Cassandra в попытке эффективно учесть все специальные случаи реализует 4 “стратегии” слияний, которые могут быть выбраны пользователем при создании таблицы:
- STCS — Size-Tiered Compaction Strategy: группирует файлы примерно одинакового размера. Триггер — количество файлов одинакового размера (по умолчанию 4).
- LCS — Leveled Compaction Strategy: организует SSTable в уровни, где каждый следующий уровень в 10 раз больше предыдущего, внутри уровня файлы не пересекаются по диапазонам ключей.
- TWCS — Time Window Compaction Strategy: разбивает SSTable по временны́м окнам и применяет STCS внутри каждого окна. Когда все данные в окне истекают по TTL, SSTable удаляется целиком.
- UCS — Unified Compaction Strategy (Cassandra 5.0): попытка объединить идеи STCS и LCS в единую параметризованную стратегию.
Как видно, UCS пытается заменить LCS и STCS, а TWCS — исключение для time series data. UCS наиболее близка к тому, что делает Vinyl. Так, в Vinyl можно задать run_size_ratio и run_count_per_level. При этом Vinyl не применяет run_count_per_level к последнему уровню LSM дерева, оставляя на нём лишь один run, что было описано в Dostoevsky paper.
Сложность выбора стратегии состоит в том, что оптимум не представим одной целевой функцией. Он состоит из достижения трёх целей, каждая из которых вступает в противоречие с двумя другими. Эти цели — read, write и space amplification.
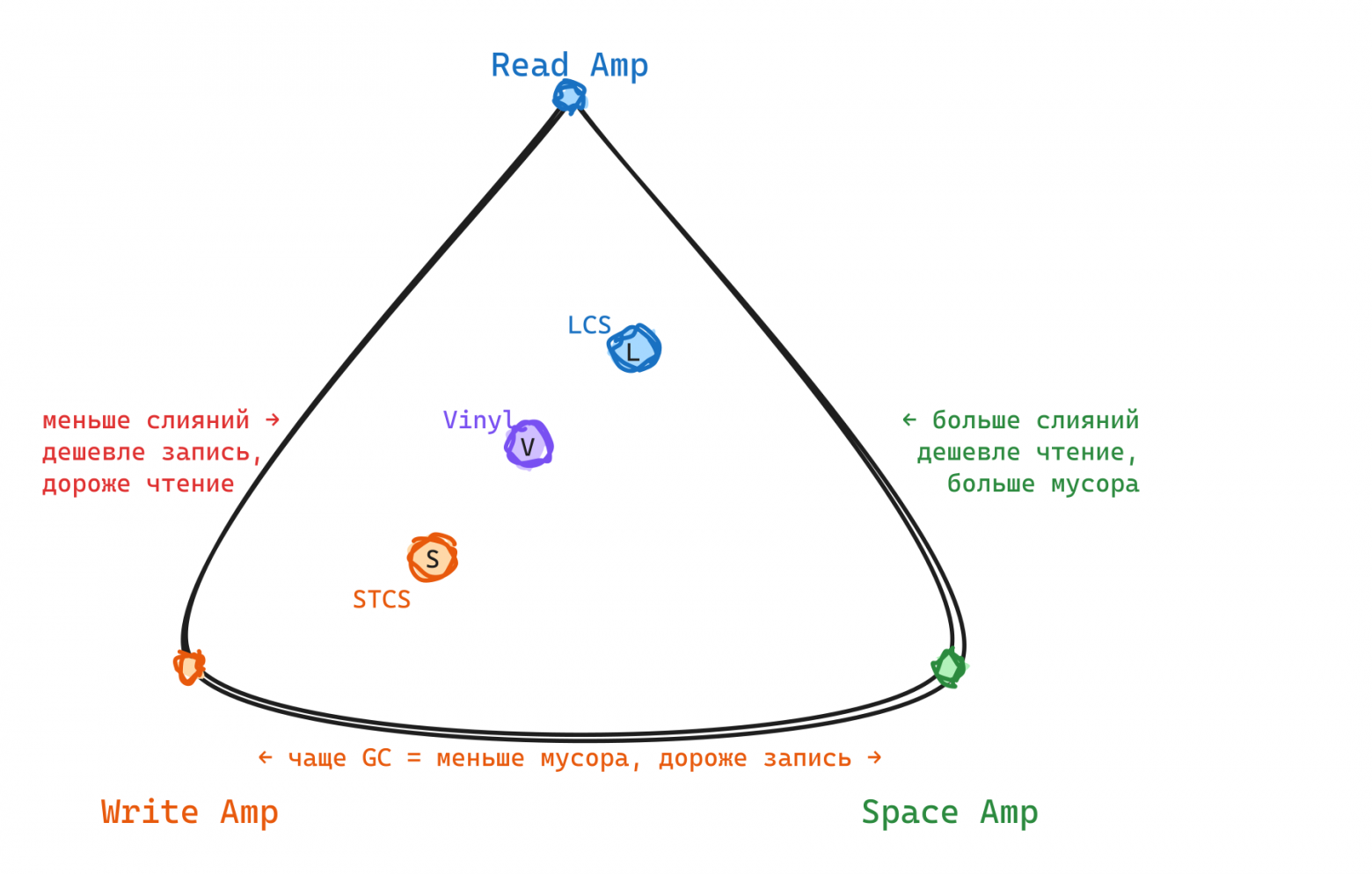
Для B-дерева с блоком 4КБ типичный read/write/space amp составляет 12-15/12-15/1.2-1.5. Для LSM-дерева: 20-30/2-3/1.5-2. Снижение write amplification требует снижения compaction, что повышает read и space amplification — и наоборот. Мы определили приоритеты для нового compaction scheduler:
- Гарантия на худший случай (OLTP-first).
- Минимизация тюнинга.
- Write amplification на первом месте (влияет на износ SSD).
- Read amplification можно конвертировать в write по тарифу 8:1.
- Space amplification — на третьем месте.
Устройство Vinyl
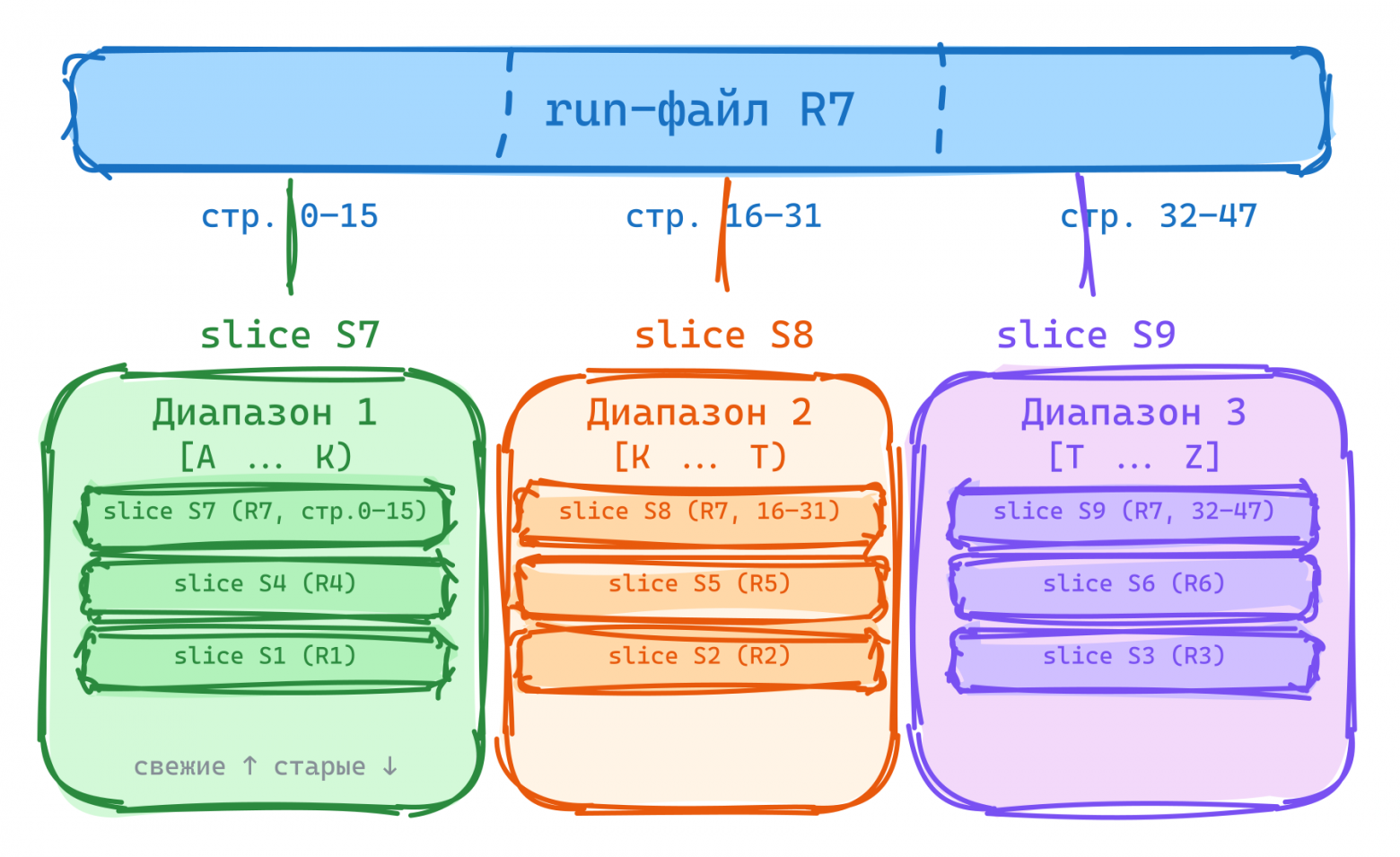
В Vinyl данные на диске хранятся в run-файлах — отсортированных файлах, аналог SST. Каждый run-файл содержит набор строк, упорядоченных по ключу. Ключевое пространство индекса разбито на непрерывные диапазоны (vy_range). Slice — это ссылка на часть run-файла. Механизм диапазонов позволяет снизить space amplification, повысить параллелизм слияний и избежать спайков.
Чтобы избежать “стадного эффекта” (все диапазоны одновременно требуют слияния), Vinyl рандомизирует стратегию слияния для каждого диапазона.
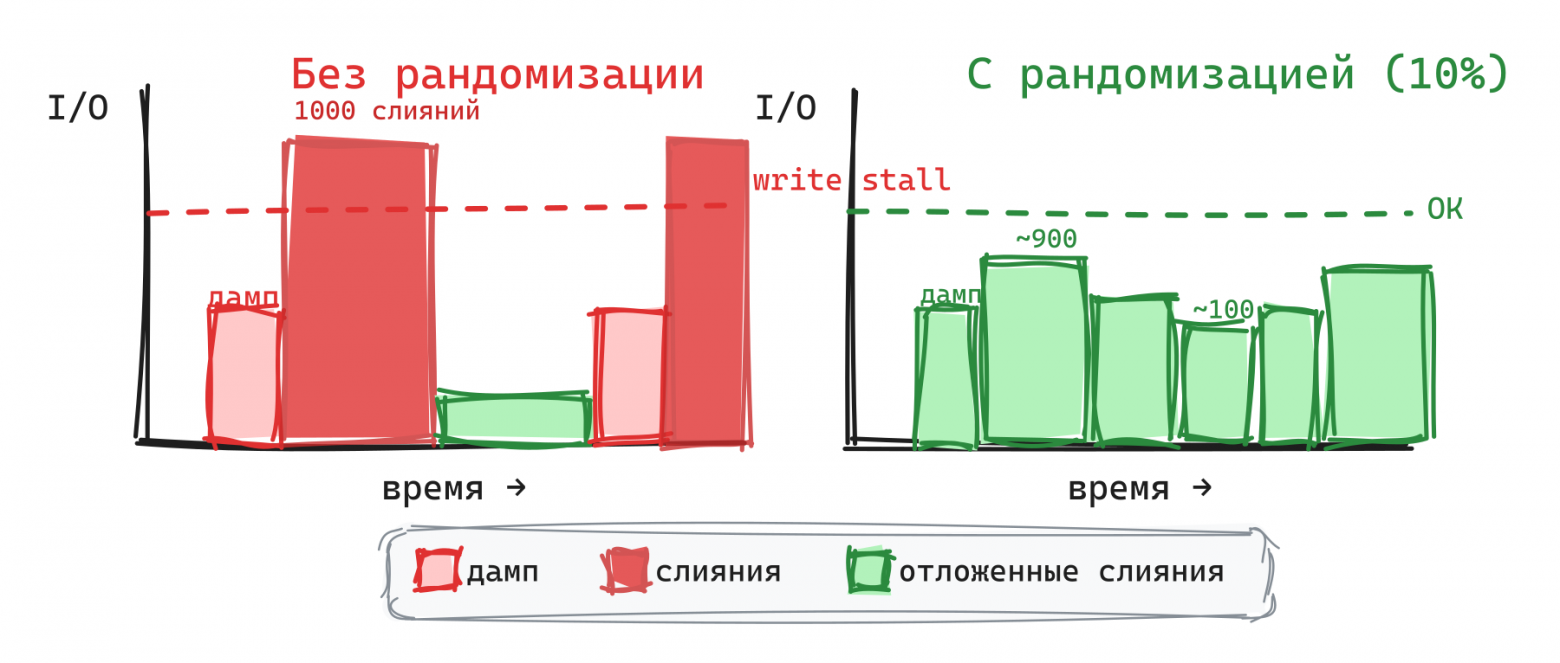
Shape-based compaction
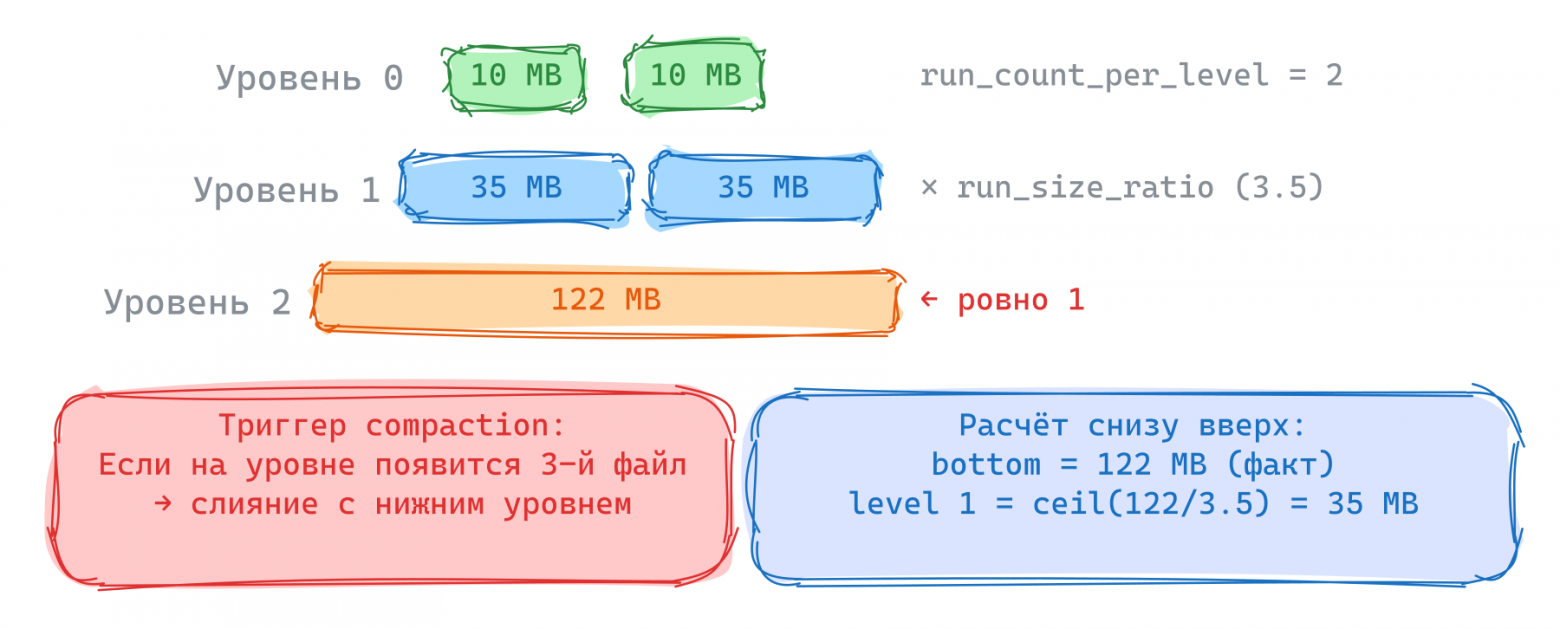
Slice в диапазоне организованы в уровни, как в LCS. Каждый следующий уровень в run_size_ratio раз (по умолчанию 3.5) больше предыдущего. На каждом уровне может быть не более run_count_per_level файлов. Последний уровень содержит не более одного файла, что гарантирует space amplification менее 1.4x.
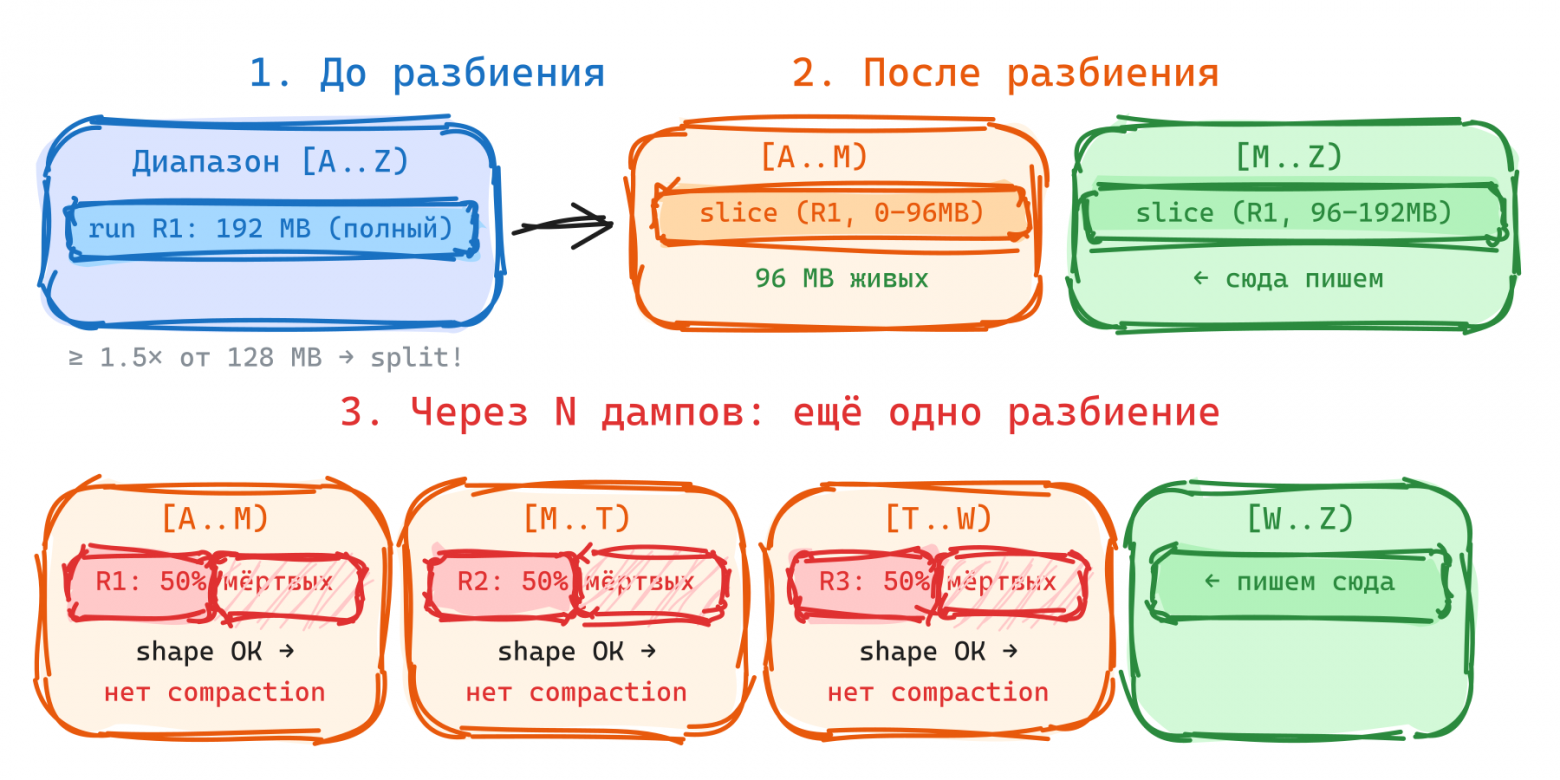
Что с этим не так: time-series bloat и квадратичные чтения
При последовательной вставке (time series) Vinyl периодически запускал бесполезные слияния. После разбиения диапазона нижняя половинка содержала лишь 50% полезных данных, а compaction scheduler считал форму “идеальной”. Объём данных на диске превышал полезный более чем в два раза, а страничные индексы мёртвых данных загружались в RAM. Вторая проблема: при удалении старых данных чтения имели квадратичную стоимость из-за отсутствия обратной связи.
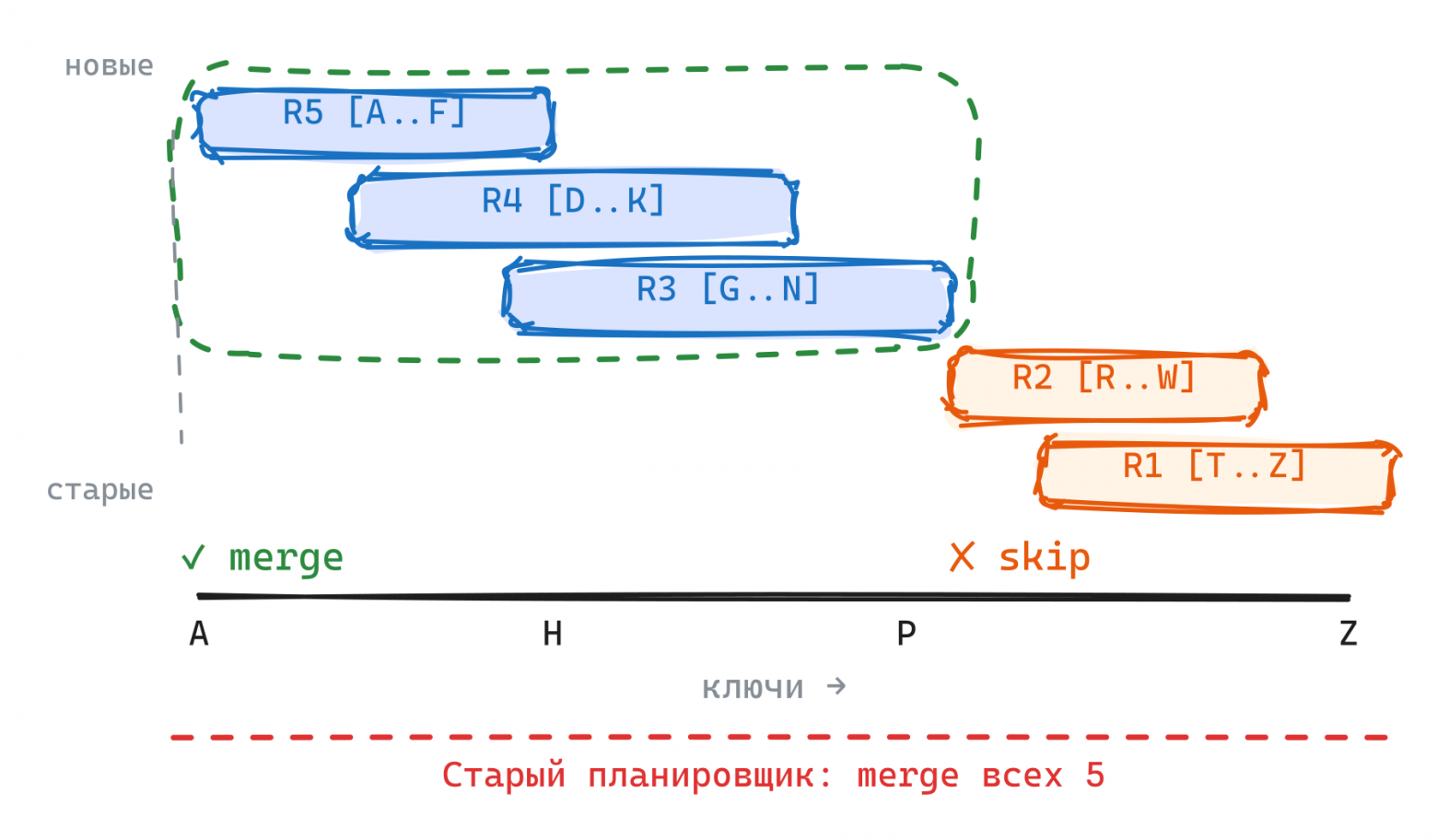
Решение: новый планировщик с явными приоритетами
Мы внедрили выбор точки разбиения, минимизирующий разрезание run-файлов, и добавили кластеризацию пересекающихся ключей. В новом планировщике:
- Compaction выбирает самый большой кластер пересекающихся run-файлов.
- Второй драйвер — read amplification (фильтрация мусора при чтении).
- Третий — space amplification (если >10% run-файла — мусор, переписываем).
Результаты бенчмарков (YCSB, 100 млн записей)
| Workload | Метрика | Baseline | Новый планировщик | Изменение |
|---|---|---|---|---|
| A (50/50, Zipfian) | RPS | 224 793 | 351 427 | +56% |
| Write Amp | 3.14x | 1.01x | -68% | |
| Space Amp | 2.11x | 1.21x | -43% | |
| Read Amp | 14.34x | 17.68x | +23% | |
| Диск | 42.1 ГБ | 24.1 ГБ | -43% | |
| B (append-only, time series) | RPS | 361 443 | 696 148 | +93% |
| Write Amp | 3.82x | 0.93x | -76% | |
| Space Amp | 7.74x | 6.94x* | не прямолинейно* | |
| Read Amp | 12.55x | 4.50x | -64% | |
| Диск | 154.9 ГБ | 138.8 ГБ | -10% | |
| Compaction I/O | 241 ГБ | 0 | -100% | |
| C (вставка+удаление+скан) | RPS | 149 723 | 129 930 | -13% |
| Write Amp | 2.49x | 1.26x | -49% | |
| Space Amp | 2.75x | 1.49x | -46% | |
| Read Amp | 12.32x | 11.81x | -4% | |
| Диск | 55.0 ГБ | 29.8 ГБ | -46% | |
Наиболее впечатляющий результат — workload B: старый планировщик тратил 4x write amplification на бесполезные слияния, новый — не трогает непересекающиеся файлы, RPS почти удваивается. По сравнению с Apache Cassandra наш движок нигде не хуже, а в ряде задач лучше по I/O и RPS.
Что впереди: страничный индекс, binary fuse8, MinHash, TTL, словарная компрессия
Мы серьёзно взялись за Vinyl. В релиз 2.11.8 уже вошли:
- Страничный индекс нового формата (.index2) — группировка метаданных в индексные блоки, кэширование по требованию (2Q-кэш). Десятки килобайт в RAM вместо сотен мегабайт.
- Binary fuse8 filter вместо классических Bloom filter — ~9 бит на ключ, высокая точность.
- MinHash-скетчи — оценка пересечения множеств ключей за O(1), избегание бесполезных слияний.
- TTL на уровне движка — автоматическое удаление устаревших строк, целиком удаляются run-файлы с истекшими данными.
- Словарная компрессия ZSTD — адаптивное обучение словаря (per-index, через
compression_dict = true). Эффективно для JSON, логов, protobuf.
Итого — новая архитектура планировщика слияний в Vinyl даёт кардинальное снижение write и space amplification, особенно на time-series и смешанных нагрузках. Всё описанное — открытое программное обеспечение. Готовые пакеты под ряд ОС доступны на нашем сайте. Я всегда на связи в чатах: @picodataru, @tarantoolru, @databaseinternalschat.
Автор статьи:

Константин Осипов
Сооснователь компании Picodata (входит в Группу Arenadata) и управляющий директор Группы Arenadata по исследованиям и разработке