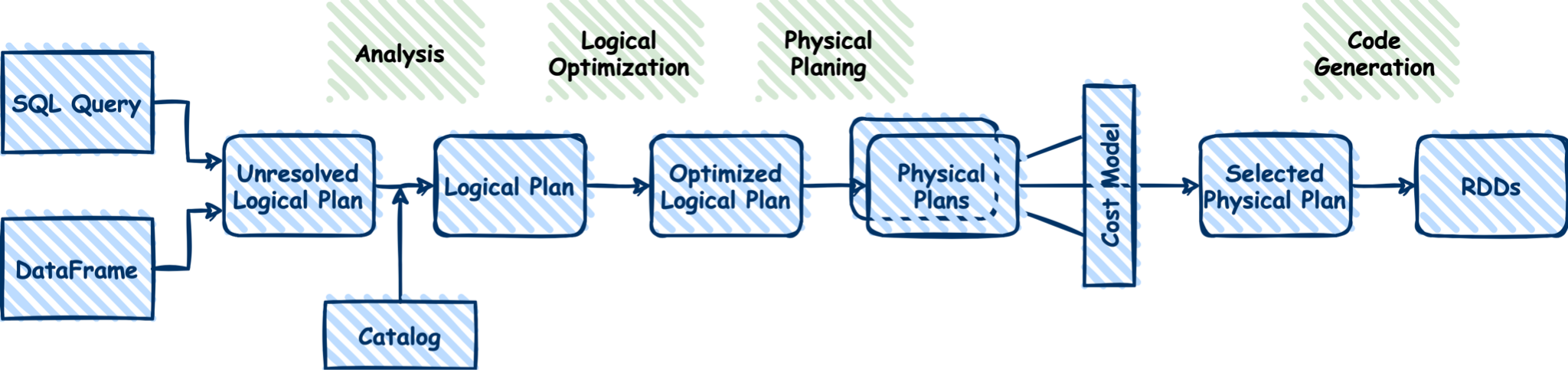
The connector uses Scala 2.11.x, 2.12.x, Twitter Finagle, and ScalikeJDBC, and runs on an HTTP server via the gpfdist protocol. Unlike other existing ADB exchange methods, this one enables parallel writing to Greenplum segments without Master participation, supports flexible partitioning when reading data from Greenplum to Spark, does not require installing the gpfdist utility on each Spark node, and offers other advantages.
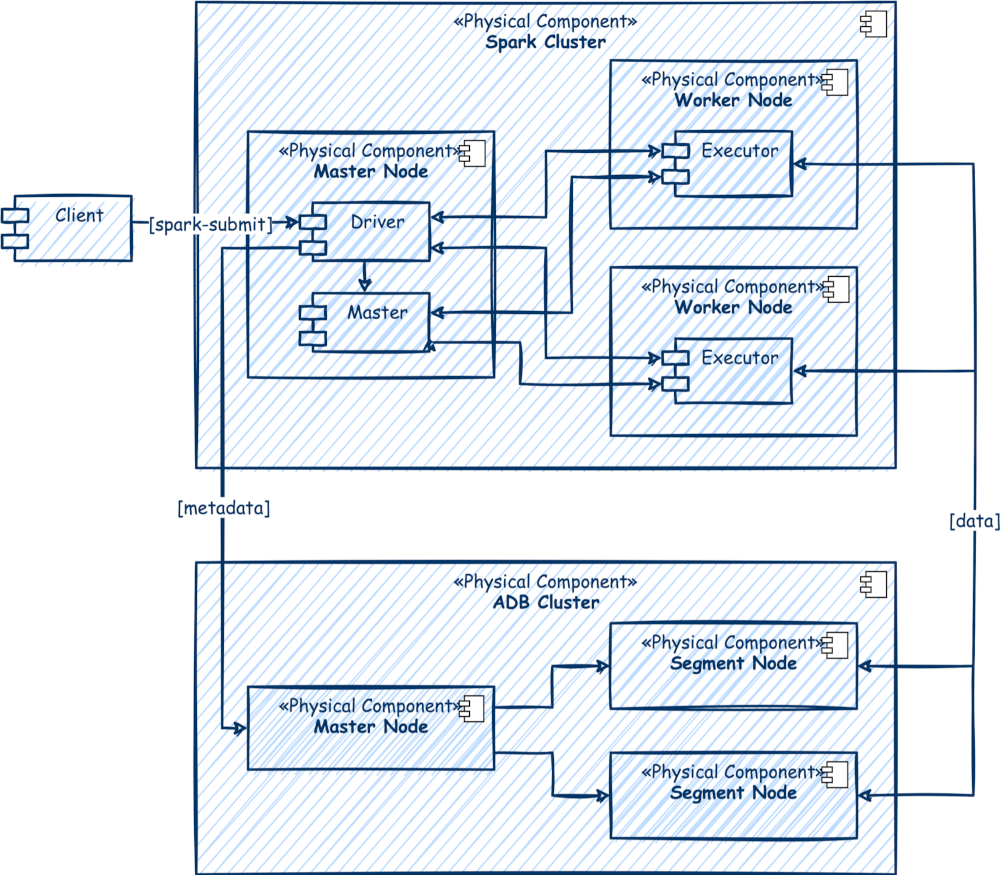
To employ gpfdist, the Finagle framework is used, which demonstrated better performance (compared to the initially selected Akka HTTP) in case of multiple simultaneous sessions from ADB segments.
ADB-Spark Connector main functions include:
- Reading data from Greenplum to Spark with various partitioning methods supported;
- Writing data from Spark to Greenplum using several write modes: Append, Overwrite, and ErrorIfExists;
- Push-down operator support;
- Extracting additional metadata from Greenplum, including statistics and data distribution schemes;
- Automatic data scheme generation;
- Optimizing the count aggregate function execution.

Dmitry Pluzhnikov
Director of System Architecture Department at Arenadata
“Our solution will be useful to those customers who combine Arenadata Hadoop and Arenadata DB when building their corporate storages. ADB-Spark Connector enables fast bidirectional communication between them and therefore the most effective data reading and writing.”
ADB-Spark Connector currently supports Spark 2.3.x and 2.4.x. The near-future plans include adding support for Spark 3.x and implementing streaming functionality.