
В отличие от OLTP-систем (Online Transaction Processing), которые ориентированы на большое количество коротких транзакций (вставка, обновление, удаление), аналитические СУБД предназначены для обработки и анализа больших объёмов информации. Для этого они используют колоночный формат хранения, сжатие данных, параллельное выполнение вычислений и специализированные алгоритмы доступа, что позволяет минимизировать нагрузку на дисковую подсистему и ускорять выполнение запросов.
В числе наиболее распространённых сегодня на российском рынке аналитических СУБД особенно интересны два проекта с открытым исходным кодом: Greenplum/Greengage и ClickHouse. Обе эти СУБД успешно закрывают широкий спектр аналитических задач, а их комбинация в едином стеке позволяет построить аналитическую систему, устойчивую к высокой пользовательской нагрузке и способную одновременно обрабатывать тысячи запросов. О том, какие архитектурные и функциональные особенности Greenplum и ClickHouse стоит учитывать, чтобы эффективно использовать их в рамках одной инфраструктуры, пойдёт речь в этой статье.
Почему одного Greenplum недостаточно
Когда заказчики обращались к нам за консультацией по планированию оптимальной архитектуры хранилища до нашего знакомства с ClickHouse, чаще всего мы останавливались на следующей классической схеме:
- Источники данных.
- Загрузка данных с помощью ETL-средств или CDC (Сhange Data Capture).
- Arenadata DB (продукт на базе Greenplum/Greengage) в качестве целевой СУБД.
- ELT-решение (NiFi или другие).
- Arenadata Hyperwave для создания хранилища слабоструктурированных и неструктурированных данных и задач дата-инжиниринга.
- BI-системы.
- Пользователи.
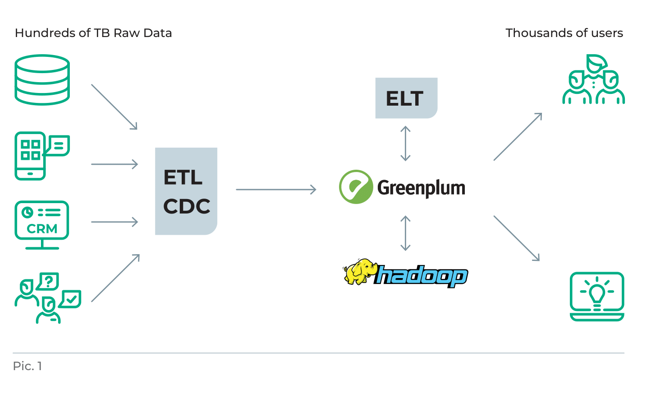
Эта архитектура показывает хорошую эффективность, когда требуется обслуживать несколько сотен параллельных запросов. В таких условиях кластер Greenplum средней производительности обеспечивает приемлемое время отклика витрин данных — от нескольких секунд до десятков секунд, в зависимости от сложности запроса и характеристик нагрузки). Однако уже в 2019 г. у нас появились заказчики, у которых были тысячи активных пользователей, и каждому из них нужно было обеспечить минимальное время отклика запросов!
Стало очевидно, что одним Greenplum здесь не обойтись. Ведь эта СУБД не может эффективно выполнять нескольких сотен конкурентных запросов и консервативно работает с запросами, которые требуют очень короткого времени отклика (например, менее секунды). Конечно, можно повышать скорость с помощью различных оптимизаций, но до определённых пределов, так как работа с такими запросами, объективно говоря, не самая сильная сторона Greenplum.
Тогда мы обратили внимание на ClickHouse и выяснили:
- в ClickHouse нет понятия транзакции;
- она не поддерживает ANSI SQL 2008;
- поддержка локальных и распределённых JOIN в ClickHouse слабо оптимизирована;
- есть сложности с выполнением операций обновления (UPDATE) и удаления (DELETE);
- отсутствует полноценный оптимизатор запросов.
Эта СУБД очень и очень быстрая! Наши тесты показали, что на сопоставимом оборудовании по скорости ответа ClickHouse оказалась значительно быстрее Greenplum при работе с WHERE-условиями, с агрегациями, без JOIN и каких-либо глубоких трансформаций.
Учитывая эти особенности, мы решили реализовать такое решение: за построение витрин данных с помощью ELT/ETL-инструментов будет отвечать Greenplum, а всю остальную работу с обработкой данных в витринах будет делать ClickHouse (см. рис. 2).
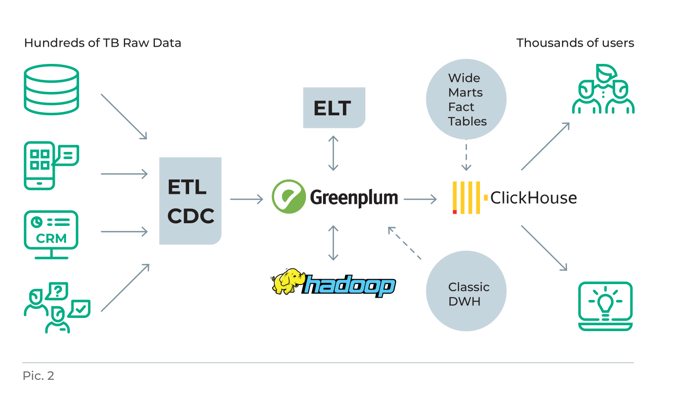
Для того, чтобы его реализовать нам было необходимо не только обеспечить быструю и корректную выгрузку данных из Greenplum в ClickHouse, но и наладить эффективное взаимодействие между ними. То есть учесть в решении задачи особенности каждой СУБД и придумать, как быстро доставлять данные из Greenplum в ClickHouse (ведь нельзя же просто взять и переложить таблицы из одной базы в другую!). Мы придумали. Но, прежде чем рассказать, как, остановимся на том, как устроены Greenplum и ClickHouse.
MPP-СУБД Greenplum
Greenplum — аналитическая распределённая массивно-параллельная СУБД с открытым исходным кодом, основанная на PostgreSQL. Она оптимальна для аналитической работы с неограниченным объёмом данных, построения больших, надёжных и масштабируемых хранилищ.
Эта СУБД отличается высокой надёжностью. Благодаря MPP-архитектуре, а также мощным алгоритмам оптимизации Greenplum позволяет очень быстро обрабатывать «тяжёлые» аналитические запросы при работе с очень большими объёмами данных. В Greenplum реализована концепция Shared Nothing (без разделения ресурсов). Каждый узел кластера участвует во всех вычислительных операциях и имеет собственные ресурсы для их выполнения (оперативную память, операционную систему, CPU и жёсткие диски). За счёт этого СУБД эффективно распараллеливает нагрузку при поступлении аналитических запросов, автоматически изолирует процессы разных пользователей друг от друга и таким образом разграничивает ресурсы кластера. Дополнительно Greenplum/Greengage обеспечивает полную поддержку транзакций в соответствии с принципами ACID, что гарантирует атомарность, согласованность, изолированность и надёжное сохранение данных. Это делает систему подходящей не только для аналитических вычислений, но и для сценариев, где требуется строгая консистентность данных, например при подготовке обязательной регламентированной отчётности, где ошибки в расчётах или несогласованность показателей недопустимы.
В 2024 г. на рынке случился неожиданный поворот: Broadcom (новый владелец VMware Tanzu и продукта Greenplum) закрыл публичные исходники Greenplum и сфокусировался на коммерческой ветке 7.x. Сообщество потеряло возможность контрибьютить в проект и лишилось площадки для обсуждения планов развития продукта и нового функционала.
Чтобы сохранить «open-source-ДНК» экосистемы Arenadata и продолжать активно развивать продукт ADB 6 и ADB 7, компания запустила собственный open source проект Greengage. Это полнофункциональный форк Greenplum 6/7, распространяемый под лицензией Apache 2.0. Уже в феврале 2025 г. в рамках этого проекта были представлены первые релизы 6.28 и 7.3, полностью совместимые с предшественником в лице Greenplum.
В ближайших релизах команда Greengage планирует активно расширять функционал Greenplum, разработка ведётся полностью открыто — все планы и актуальные задачи доступны в публичной дорожной карте проекта. Ознакомиться с ним, а также с документацией и свежими материалами можно по ссылкам:
Архитектура Greenplum/Greengage
Архитектура Greenplum/Greengage представляет собой несколько экземпляров (инстансов) объектно-реляционной базы данных PostgreSQL, которые работают как единая СУБД.
Элементами такой архитектуры являются:
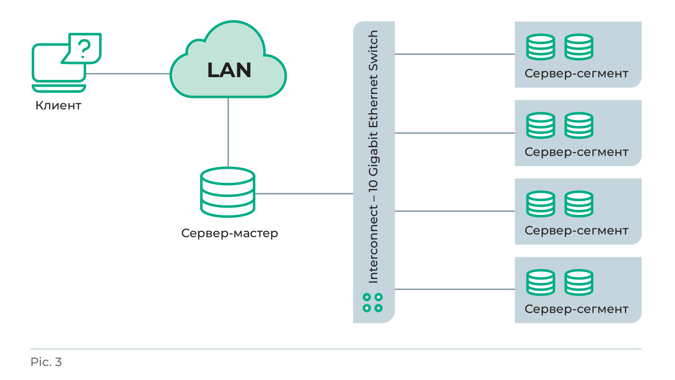
- Мастер-хост (или мастер-сервер). На нём развёрнут мастер-сегмент (master instance, «мастер») — главный экземпляр PostgreSQL. Это точка входа в Greenplum: к ней подключаются пользователи и в неё приходят все SQL-запросы. «Мастер» не содержит никаких пользовательских данных и практически не участвует в их обработке. Он лишь принимает входящие подключения, анализирует и готовит план выполнения, перераспределяя их дальше по сегментам. Мастер-сегмент координирует свою работу с другими экземплярами базы данных.
- Резервирует мастер (secondary master instance) на случай выхода его из строя. Экземпляр PostgreSQL, который используется, когда недоступен основной «мастер».
- Primary segment instance на сервер-сегментах (segment hosts). На одном сервер-сегменте может размещаться один или несколько (обычно от двух до восьми) логических сегментов (экземпляров PostgreSQL), которые хранят и обрабатывают данные. Каждый сегмент содержит свою часть данных, а процессы, его обслуживающие, выполняются в соответствующих экземплярах сегмента. Сегментные сервера взаимодействуют между собой и “мастером” и извне недоступны. Предполагается, что все сервер-сегменты должны быть настроены идентично, так как наилучшая производительность Greenplum/Greengage достигается за счёт равномерного распределения данных и нагрузок.
- Mirror segment instance («зеркало»). Экземпляр PostgreSQL, являющийся зеркалом одного из логических сегментов. Для каждого из логических сегментов может быть только одно зеркало.
- Interconnect network (сетевой уровень архитектуры Greenplum/Greengage). Связь между отдельными экземплярами PostgreSQL обеспечивается за счёт соединения сегментов с помощью интерконнектов. Использование нескольких interconnect-сетей позволяет повысить пропускную способность канала и обеспечить отказоустойчивость кластера (в случае отказа одной из сетей весь трафик перераспределяется между оставшимися).
Сильные стороны Greenplum/Greengage:
- Поддержка ANSI SQL 2008 + 2012 extensions (OLAP и т. д.).
- Возможность выполнять локальные и распределённые JOIN.
- Поддержка реляционной модели данных, совместимость с PostgreSQL, а значит, и со всеми BI- и ETL-системами. Знакомый синтаксис SQL, который обеспечивает недорогую ETL-разработку.
- Соответствие требованиям ACID:
- Atomicity (атомарность) — гарантия, что каждая транзакция будет или выполнена полностью, или не выполнена вовсе.
- Consistency (согласованность) — гарантия того, что до выполнения транзакции и после база останется согласованной (консистентной).
- Isolation (изолированность) — гарантия того, что параллельные транзакции не оказывают влияния на результат выполнения отдельной транзакции.
- Durability (неизменяемость операций) — гарантия того, что внесённые изменения не будут отменены после подтверждения от системы, что транзакция выполнена.
- Отказоустойчивость, которая обеспечивается благодаря созданию зеркал каждого логического сегмента и резервного мастер-сервера.
- Горизонтальное масштабирование — возможность добавлять новые серверы и сегменты практически без простоя СУБД. Чем больше новых узлов добавлено, тем быстрее работает Greenplum.
- Возможность работать с данными из нескольких источников с минимальной предварительной обработкой.
- Поддержка построчного хранения для изменяющихся данных и колоночного формата хранения, эффективного для OLAP-нагрузок.
- Сжатие данных встроенными средствами, позволяющее экономить место и ускорять операции за счёт уменьшения объёма чтения с диска.
Типовые сценарии применения Greenplum/Greengage:
- Системы регулярной отчётности (управленческой, операционной, МСФО и т. д.).
- Предиктивный анализ: анализ текущих и прошлых данных или событий для прогноза будущих данных или событий. Например, в директ-маркетинге, целевой рекламе, управлении инвестиционными рисками, выявлении мошеннических схем.
- Ad-hoc аналитика: сегментация рынка, концепция продукта, эффективность рекламы, потенциал компании или бренда, каналы сбыта, эффективность продаж.
- Маркетинговый анализ: целевая аудитория, конкуренты, ценовые предложения.
- Финансовый скоринг: оценка кредитоспособности заёмщиков, оценка наиболее вероятных финансовых действий и др.
- Анализ клиентской базы: АВС-анализ (сегментация по объёму продаж и прибыли), XYZ-анализ (сегментация по частоте покупок или сделок).
- Анализ данных логистики: сроки доставки, затраты на перевозку, расходы на хранение груза.
Вклад Arenadata в развитие проекта Greenplum
До закрытия публичного репозитория Greenplum компанией Broadcom именно Arenadata занимала лидирующие позиции среди независимых контрибьюторов: в 2022 году на её долю приходилось 44% всех принятых Pull Request в ядро проекта (на втором месте Alibaba с 15%). Аналогичное лидерство отмечалось и в 2021 году.
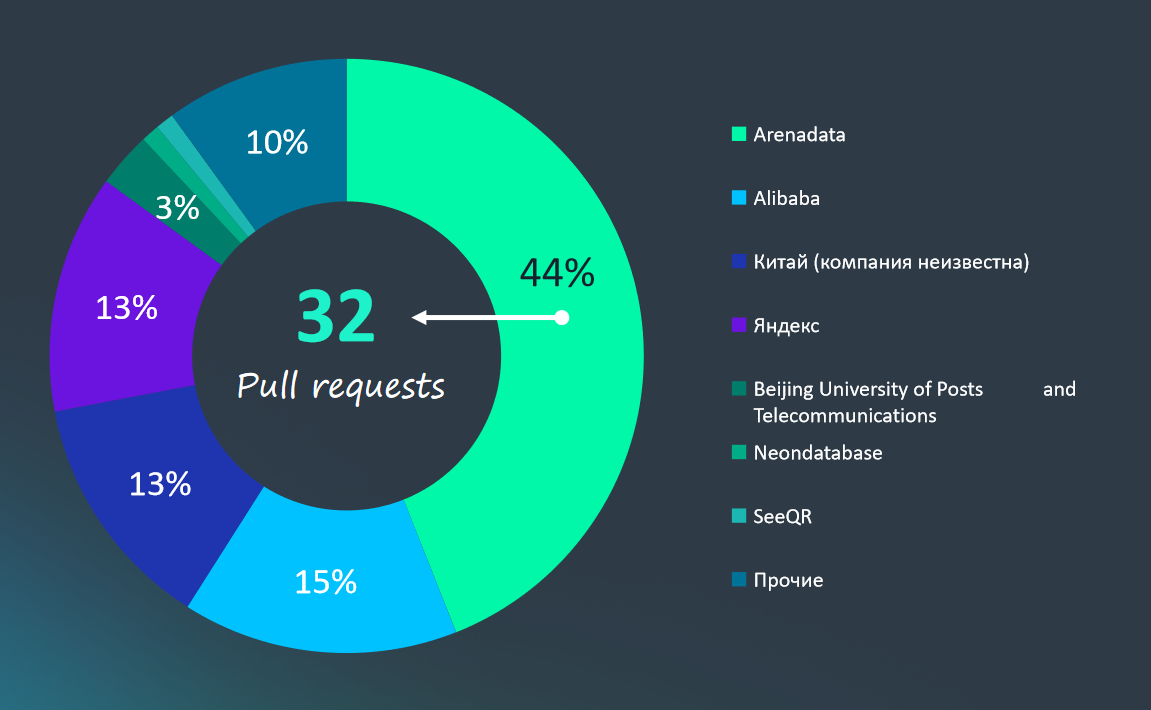
Исследование Arenadata-2023
Среди наиболее значимых доработок, внесённых специалистами Arenadata в Greenplum за последние годы, можно выделить:
- Поддержку алгоритма сжатия Zstandard (ZSTD) для колоночных таблиц, позволяющего снизить нагрузку на CPU и уменьшить TCO при работе с большими объёмами данных.
- Фильтр pushdown в PXF, который переносит вычисления на сторону источника данных и значительно ускоряет выполнение запросов к внешним системам (SAP Hana, Oracle и др.), а также реализацию федеративного слоя поверх Greenplum.
- Стабилизацию Greenplum 6 — устранение багов, связанных с новой функциональностью (WAL-репликация, REPLICATED-таблицы, BITMAP-индексы, обновлённый ORCA), и работа с оптимизатором на уровне ядра PostgreSQL.
- Реализацию конфигурационного параметра с таймером, автоматически прерывающего выполнение запроса, если клиент отсоединился.
Дополнительный функционал в Arenadata DB
Enterprise-версия Arenadata DB (ADB) — это промышленная MPP-СУБД, ориентированная на корпоративные хранилища данных и работу с объёмами в сотни терабайт. Она используется там, где требуются сложные аналитические запросы, ad-hoc-аналитика, соединение больших таблиц и выполнение функций на процедурных языках. Продукт особенно востребован у банков, ритейла, телеком-операторов, производственных компаний и онлайн-сервисов, включая объекты КИИ.
По сравнению с open source и сторонними сборками ADB обеспечивает расширенный функционал: двусторонние коннекторы (с Kafka, ClickHouse, Spark и другими кластерами Greenplum/ADB), ADB Control для мониторинга на уровне запросов, систему управления бинарными резервными копиями (ADBM) и реализацию DR-кластеров на основе физических бэкапов. Также поддерживаются офлайн-установка, управление развёртыванием и обновлением ПО, расширение кластеров без простоя, развитый мониторинг и alerting.
Отдельным компонентом продукта является система мониторинга ADB Control. Она обеспечивает отслеживание статуса и прогресса выполнения запросов, возможность их отмены, поиск тяжёлых операций по потреблению CPU, RAM или Spill, а также выявление перекосов (skew) по сегментам в части распределения данных, ресурсов и операций чтения/записи. Кроме того, ADB Control поддерживает настройку и мониторинг лимитов ресурсных групп, а также визуализацию изменений ключевых метрик во всех подключённых кластерах.
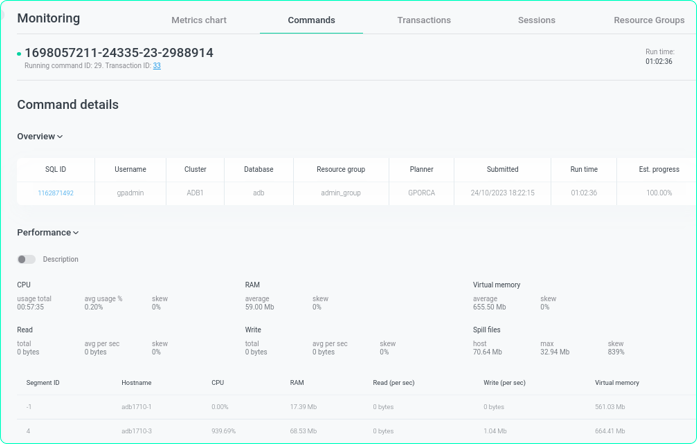
ADB проходит полный цикл тестирования, сертифицирован ФСТЭК по 4-му и 6-му уровню доверия и поддерживается командой Arenadata в режиме 24/7. Заказчики получают доступ к 3-й линии поддержки, консалтингу (пусконаладка, аудит, технадзор), обучающим курсам и документации. Вендор выступает единой точкой ответственности (Single Throat to Choke) — от запуска и сопровождения до развития продукта, обеспечивая SLA на инциденты, возможность георезервирования и прозрачное планирование развития через дорожную карту.
Аналитическая СУБД ClickHouse
ClickHouse — это высокопроизводительная колоночная СУБД с открытым исходным кодом, разработанная для обработки аналитических запросов к большим объёмам структурированных данных в режиме реального времени. Изначально эта технология использовалась для построения интерактивных отчётов в «Яндекс Метрике». Постепенно использование ClickHouse распространилось на другие отделы компании, а потом и на внешних пользователей (после расширения пользовательской базы проект стал открытым).
Наиболее значимая особенность ClickHouse — очень высокая скорость выполнения SQL-запросов на чтение. Это самая быстрая колоночная OLAP-СУБД для своих типов запросов, которая способна масштабироваться до десятков триллионов записей с совокупным объёмом данных в несколько петабайт. ClickHouse позволяет сохранять поток данных без предварительной агрегации и быстро получать отчёты в любых разрезах, интерактивно выполнять аналитические запросы к данным, обновляемым в режиме реального времени.
В отдельных областях применения ClickHouse может быть выгоднее других систем ещё и с точки зрения эффективности использования ресурсов.
Из других значимых особенностей ClickHouse — ограниченная поддержка транзакций, сложности с точечными операциями UPDATE и DELETE, а также отсутствие полноценного оптимизатора запросов. Вместе с тем ClickHouse оптимизирован для массовой загрузки данных: вставка строк большими пачками выполняется значительно эффективнее, чем поштучные операции.
Архитектура ClickHouse
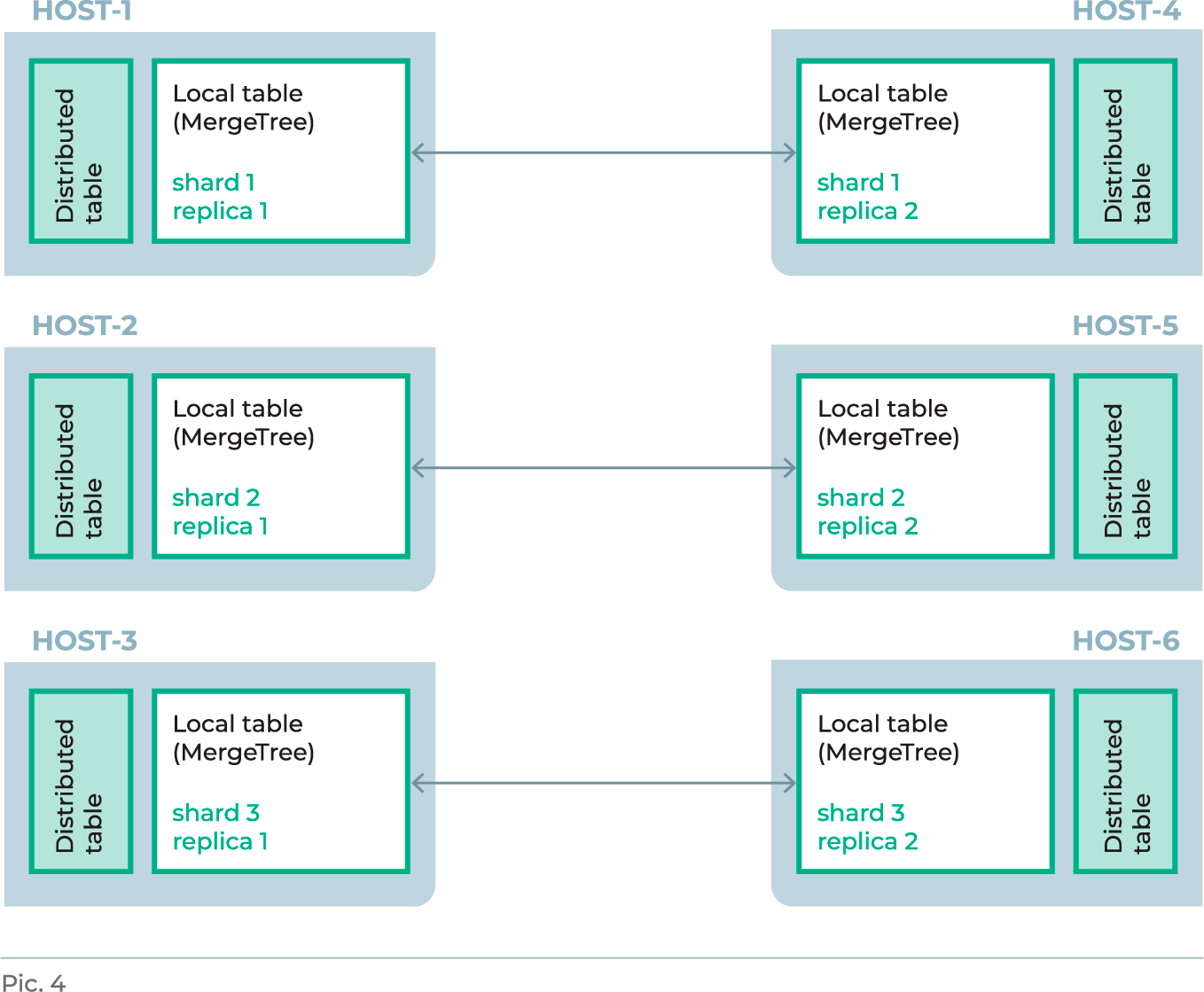
Архитектура отличается от Greenplum/Greengage: на каждом сервере устанавливается один экземпляр СУБД и пользовательские запросы обрабатываются напрямую этими серверами. Для репликации данных и выполнения распределённых DDL-запросов ClickHouse может использовать как ClickHouse Keeper — встроенный сервис координации, так и Apache ZooKeeper, который продолжает поддерживаться и применяться в продакшен-средах. Keeper является функциональной альтернативой ZooKeeper, но реализован на C++ и глубже интегрирован в экосистему ClickHouse.
ClickHouse Keeper vs ZooKeeper
- Язык реализации: ZooKeeper написан на Java, ClickHouse Keeper — на C++.
- Совместимость: клиент ZooKeeper может работать с ClickHouse Keeper, но форматы журналов и снапшотов несовместимы; смешанный кластер создать нельзя.
- Протоколы: межсерверный протокол ClickHouse Keeper отличается от ZooKeeper.
- Управление доступом: ACL реализован по тому же принципу.
Таким образом, ClickHouse Keeper можно рассматривать как встроенную альтернативу ZooKeeper, более тесно интегрированную с ClickHouse.
Высокая скорость работы ClickHouse достигается за счёт определённых архитектурных особенностей:
- Векторные вычисления по участкам столбцов. Данные не только хранятся в столбцах, но и обрабатываются по векторам или по частям столбцов. Это снижает издержки на диспетчеризацию и позволяет эффективнее использовать CPU.
- Данные в таблицах ClickHouse всегда физически сортируются по первичному ключу, что позволяет эффективно извлекать отдельные значения или диапазоны.
- Распараллеливание операций на несколько ядер процессора одного сервера.
- Распределённые вычисления на кластере за счёт шардирования.
- Поддержка приближённых вычислений с помощью агрегатных функций. Это снижает количество обращений к жёсткому диску и тоже повышает скорость обработки.
- Семплирование данных — выполнение запросов на части выборки, а также возможность агрегации ограниченного количества случайных ключей.
Особенности ClickHouse
Очень и очень высокая скорость обработки запросов!
ClickHouse обрабатывает OLAP-запросы в десятки тысяч раз быстрее, чем многие другие системы*: её производительность достигает терабайтов данных в секунду. Например, в «Яндекс Метрике» были зафиксированы такие показатели: до 1 миллиарда строк в секунду на одном сервере и до двух терабайт в секунду на кластере из 400 узлов. Такая скорость обработки изменила подход к работе аналитиков и Data Science.
* Бенчмарки ClickHouse’а можно посмотреть здесь.
Линейная масштабируемость.
Для увеличения степени конкурентности и масштабируемости достаточно добавить новые узлы в кластер. Это позволяет обрабатывать больше параллельных запросов и распределять нагрузку между серверами.В ClickHouse можно настроить межцодовую репликацию, используя стандартные механизмы репликации таблиц и координацию через ClickHouse Keeper или ZooKeeper. Такой подход позволяет синхронизировать данные между несколькими дата-центрами, повысить отказоустойчивость системы и обеспечить доступ к данным даже при выходе из строя одного из ЦОД.
Высокая доступность и отказоустойчивость.
Все данные пользовательского кластера в ClickHouse всегда доступны на чтение и запись. Поскольку это полностью децентрализованная система, с её помощью можно построить СУБД с любым уровнем отказоустойчивости. Например, разместив данные в трёх дата-центрах и наладив репликацию, можно получить кластер с фактором репликации Х2, который способен выдержать полный отказ одного дата-центра.
Асинхронная репликация по умолчанию.
В ClickHouse по умолчанию используется асинхронная репликация. Это значит, что если данные записаны в любую реплику, то они будут гарантированно скопированы в другие реплики. Асинхронная репликация в ClickHouse работает в фоновом режиме и обычно занимает несколько секунд. Она позволяет поддерживать полную идентичность данных на разных репликах, автоматически восстанавливая их после сбоев. При необходимости можно использовать имитацию синхронного режима репликации. Для повышения надёжности асинхронной репликации в СУБД возможен кворумный режим записи данных. В этом случае запись считается успешной только после того, как информация корректно записана на несколько серверов — «набран кворум». Так обеспечивается линеаризуемость и имитация синхронных реплик. Если количество реплик с успешной записью не достигнет заданного кворума, то запись считается не состоявшейся и ClickHouse сам удалит этот блок из всех реплик для обеспечения целостности данных.
Быстрое сжатие данных.
Поскольку ClickHouse является колоночной СУБД, технология сжатия данных в ней работает в сотни раз быстрее, чем в строчных базах. За счёт использования современных алгоритмов компрессии LZ4 и ZSTD данные не только занимают меньше места в хранилище, но и значительно быстрее обрабатываются.
Поддержка SQL и расширяемость.
ClickHouse поддерживает диалект структурированного языка запросов, близкий к стандарту ANSI SQL, c расширениями, включающими в себя:
- массивы и вложенные структуры данных,
- вероятностные структуры,
- URI-функцию,
- возможность подключить внешнее key-value хранилище.
Также благодаря HTTP-интерфейсу можно писать собственные коннекторы на любом языке программирования. А благодаря специальным интеграционным движкам (engines) в качестве источника данных ClickHouse может использовать множество внешних хранилищ и баз данных.
Поддержка массивов и кортежей.
В ClickHouse «из коробки» поддерживаются массивы и кортежи. СУБД позволяет создавать таблицы данных с поддержкой на уровне запросов, где в одной из колонок, например, будет массив данных (множество чисел) или кортеж — массив из нескольких полей.
Возможности интеграции.
ClickHouse может подключаться к любой базе данных по JDBC и использовать её таблицы как свои. Также она может подключаться к другим экземплярам ClickHouse без дополнительной настройки, есть готовые интеграции с другими системами. В качестве инструментов подключения к СУБД можно использовать консоль, HTTP API, драйверы JDBS и ODBC и множество «обёрток» (wrapper) на Python, PHP, NodeJS, Perl, Ruby и R.
Работа с таблицами.
В ClickHouse ключевым элементом архитектуры являются движки таблиц. Они определяют, как данные будут храниться, индексироваться и обрабатываться внутри СУБД. Для разных сценариев предусмотрены разные движки: одни оптимизированы для работы с временными таблицами или внешними источниками, другие — для долговременного хранения и аналитики.
Наиболее распространённым и функциональным является движок MergeTree, лежащий в основе большинства производственных сценариев использования ClickHouse.
Движок таблиц MergeTree позволяет:
- осуществлять неблокируемые запись и чтение;
- вставлять миллионы записей в секунду;
- партиционировать, реплицировать и семплировать данные;
- создавать таблицы и базы данных в runtime;
- загружать информацию, выполнять запросы без переконфигурирования и перезапуска сервера.
- Аналитика работы мобильных приложений — анализ количества скачиваний и регистраций, активности и вовлечённости пользователей, длительности сессий, количества рассылаемых приглашений и т. д.
- Web-аналитика — источники трафика, отказы, новые, постоянные и вернувшиеся посетители, длительность сессии, среднее количество просмотра страниц за один визит, конверсия, выполняемые действия, используемые устройства (мобильные или десктопные).
- Реклама и торги в реальном времени — технология продажи и покупки рекламных показов через аукцион.
- Розничная и электронная торговля — анализ покупательского спроса, учёт и анализ товарных запасов на складе, сбор и анализ данных онлайн-покупок пользователей и др.
- Бизнес-аналитика, банковские и финансовые операции — клиенты, финансы, продукты.
- Мониторинг различных технических и бизнес-метрик.
- Телекоммуникации и информационная безопасность — сбор и анализ информации об актуальных угрозах, выдача рекомендаций по их предотвращению, определение уязвимых мест в ИТ-инфраструктуре, сбор данных об используемом ПО и сроках действия лицензий.
- Онлайн-игры — активные пользователи, длительность сессии, отток, цена за установку, платежи и т. д.
- Обработка данных с IoT-устройств (Internet of Things, интернет вещей) и промышленных датчиков — обработка показателей с промышленных роботов, мониторинг линий производства в реальном времени.
ClickHouse 2025: актуальные возможности и «фишки» enterprise-дистрибутива
20 марта 2025 г. вышел новый релиз ClickHouse 25.3 LTS (долгосрочный поддерживаемый выпуск, рекомендованный для production-кластеров) который включал в себя 18 новых функций, 13 улучшений производительности и 48 исправлений багов.
Среди значимых нововведений:
- В экспериментальном режиме реализована интеграция с Unity Catalog и AWS Glue service catalog для поддержки DeltaLake и iceberg-формата таблиц.
- Поддержка типов данных JSON/Dynamic/Variant переведена в статус production-ready.
Вклад Arenadata в развитие проекта ClickHouse
Поскольку отдельные разработки мы возвращаем в комьюнити исходного проекта, часть нового функционала, который Arenadata реализовала для Arenadata QuickMarts, сейчас доступна всему сообществу ClickHouse.
В частности, в релиз ClickHouse 20.8 был включён созданный Arenadata функционал kerberos-авторизации для Kafka. Это позволило настраивать авторизацию в ClickHouse (и Arenadata QuickMarts соответственно): конфигурационный файл ClickHouse управляет библиотекой librdkafka, обеспечивающей взаимодействие с Kafka. Основная сложность этой разработки была связана с тем, что в ClickHouse изначально было заложено минимальное количество внешних зависимостей. Стандартный для продукта способ использования библиотек — полная интеграция. Также в этом релизе нашей командой были решены некоторые технические проблемы, которые дали возможность комьюнити проекта полноценно использовать Kerberos в ClickHouse. Потребовалось много усилий для создания окружения из docker-контейнеров с Kafka, ZooKeeper и Kerberos KDC для тестирования этого функционала.
В релизе ClickHouse 21.1 вышла реализация kerberos-авторизации доступа к HDFS, сделанная нашей командой. А в ClickHouse 21.11 появилась функция OR operator in ON section for join. Для ClickHouse это был важный шаг в направлении полной поддержки стандарта SQL. Для нашей команды эта задача стала своего рода тестом на возможность внесения изменений на уровне ядра ClickHouse (обычно такие вещи делает только разработчик исходного проекта).
В течение 2023 и 2024 года был решён ряд задач и сделано несколько коммитов в рамках разработок по информационной безопасности и сертификации продукта ADQM во ФСТЭК. Был доработан функционал контроля ограничения количества неуспешных попыток подключения и сделан ряд доработок в рамках решения задачи по безопасному хранению паролей.
Дополнительный функционал в Arenadata QuickMarts
Часть нового функционала остаётся уникальной и доступна нашим заказчикам только в составе enterprise-версии Arenadata QuickMarts. В частности, благодаря коннекторам наш продукт нативно совместим с ADB и ADH.
Кроме коннекторов, в enterprise-редакции ADQM также реализованы упрощённые установка, настройка и обновление сервисов с помощью Arenadata Cluster Manager и система мониторинга и оповещения на базе Prometheus и Grafana. Она помогает администраторам оставаться в курсе того, что в конкретный момент времени происходит с кластером. Система оповещений позволяет предупреждать сбои и ошибки в работе системы.
Как и в случае других продуктов компании, в рамках разработки Arenadata QuickMarts мы проводим всестороннее тестирование и контроль качества выпускаемых релизов. У наших заказчиков есть возможность влиять на формирование дорожной карты развития продукта.
Для повышения эффективности эксплуатации Arenadata QuickMarts мы разработали дополнительный продукт — ADQM Control. Он обеспечивает комплексный мониторинг, анализ и администрирование кластеров ADQM/ClickHouse:
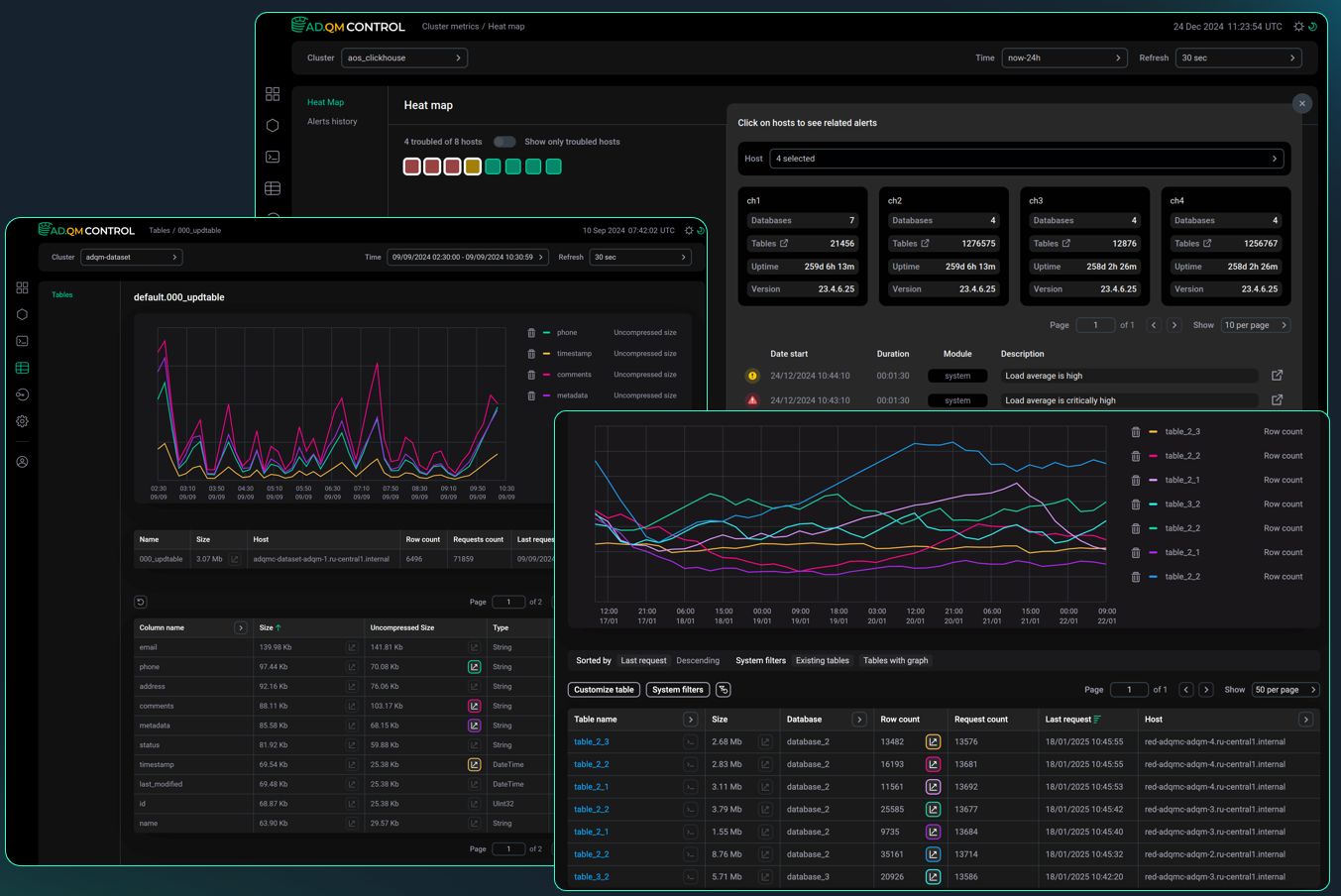
- Мониторинг состояния кластеров на основе системных и сервисных метрик: heat map для визуализации состояния всех хостов, гибкая настройка оповещений и инцидентов, хранение истории событий.
- Контроль состояния СУБД с анализом таблиц и колонок, выявлением редко используемых данных и рекомендациями по оптимальному выбору кодеков сжатия.
- Анализ пользовательских запросов: сбор метрик (пользователь, синтаксис, длительность, потребляемые ресурсы), визуализация нагрузки, диагностика ошибок.
- Управление доступом и пользователями: базовый функционал управления учётными записями и парольными политиками.
- Поддержка SSL для защиты каналов обмена данными между всеми компонентами сервиса.
Техническая поддержка Arenadata QuickMarts оказывается в режиме 24/7. Мы строго соблюдаем SLA: в договоре фиксируется время первого ответа на обращение, гарантии по оперативной диагностике и устранению сбоев, развёрнутые консультации и помощь в установке обновлений.
Заказчики enterprise-версий имеют возможность передать планирование и реализацию проектов внедрения в руки экспертов. В этом случае работы выполнят архитекторы, аналитики и инженеры Arenadata в рамках различных пакетов консалтинговых услуг: от классических услуг, включающих техническую экспертизу для обеспечения качественного внедрения продуктов Arenadata, до специальной программы приоритетного внимания вендора. Обладая глубоким пониманием потребностей заказчиков, консалтинг Arenadata выступает в роли доверенного советника и сопровождает клиентов на всех этапах реализации проекта.
Greenplum vs ClickHouse (сравнительная таблица)
| Greenplum | ClickHouse | |
| ACID (транзакционность) | Хорошо | Нет |
|
Возможность запускать несколько запросов в рамках одной транзакции. В Greenplum обеспечивается полная ACID-изоляция. В ClickHouse понятия транзакции не существует |
||
| Работа с запросами по WHERE-условиям | Хорошо | Отлично! |
|
Greenplum: в зависимости от объёма данных в базе выдаёт ответ за несколько единиц или десятков секунд.
|
||
| FULL SCANS | Хорошо | Отлично! |
|
Режим FULL SCANS подразумевает полное сканирование всей базы данных с последующей выдачей объёмного запроса на внешний ресурс. У Greenplum с этим режимом работы всё хорошо, но ClickHouse благодаря своим агрегативным и лямбда-функциям работает намного быстрее |
||
| ANSI SQL | Отлично! | Минимально |
|
Greenplum поддерживает ANSI SQL 2008 + 2012 extensions (OLAP и т. д.). В целом он соответствует PostgreSQL 9.4 (на декабрь 2019 г.). В ClickHouse поддержки ANSI SQL почти нет: поддерживается только ограниченное количество запросов ANSI SQL. |
||
| Работа с JOIN | Отлично! | Минимально |
|
Greenplum корректно работает как с локальными, так и с распределёнными JOIN. Иногда случаются небольшие проблемы с JOIN-индексами (Greenplum не всегда их использует в JOIN). В ClickHouse работа с JOIN реализована слабо. Во-первых, правая часть JOIN должна помещаться в память одного сервера. А объединить две таблицы объёмом больше, чем память одного сервера, невозможно. Во-вторых, в ClickHouse планировщик не может решить, какой тип JOIN ему нужно выполнять в данном контексте. Поэтому всегда приходится указывать нужный тип: не правый или левый, а локальный, глобальный, any и т. д. Пользователь, который не знает об этой особенности, рискует получить неконсистентные данные |
||
| Управление ресурсами | Отлично! | Средне |
|
Алгоритм управления ресурсами реализован в Greenplum очень гибко. Можно назначать конкретным группам пользователей конкретные ресурсы, причём они могут даже заимствовать их друг у друга по определённым правилам. Это достигается благодаря новому механизму ресурсных групп (есть ещё старый механизм — ресурсные очереди, которые работают менее стабильно) |
||
| Отказоустойчивость | Хорошо | Хорошо |
| Катастрофоустойчивость (disaster recovery) | плохо, ADB (Хорошо) | Хорошо |
| Ролевая модель | Хорошо | Минимально |
|
В Greenplum повторены классические модели PostgreSQL: есть пользователи, группы, разрешения и наследование, есть поддержка шифрования данных и SSL-протокола подключения, можно реализовать roll down security и call down security. В ClickHouse ничего подобного нет, но появилась функция, позволяющая решить задачу авторизации (об этом будет ниже). |
||
| Custom code | Отлично! | Средне |
|
Под Custom code имеется в виду запуск не стандартного SQL-кода, а длинных пользовательских инструкций, написанных на основе SQL.
|
||
ADB ClickHouse Connector 2.0 — ключевые отличия от Tkhemali
В отличие от предыдущей версии коннектора Tkhemali 1.X, основанной на механизме внешних (external) таблиц, ADB ClickHouse Connector реализован на базе foreign data wrapper и foreign-таблиц. Благодаря этому новая версия коннектора к ADQM/ClickHouse обладает следующими функциональными возможностями:
- Более удобная и безопасная схема управления учётными данными. Если в предыдущей версии коннектора учётные данные пользователей необходимо было прописывать в параметре LOCATION на уровне каждой внешней таблицы либо в файле в явном виде, в ADB ClickHouse Connector логин и пароль пользователя хранятся в отдельном объекте базы данных ADB — user mapping.
- Многоуровневые настройки соединения. Общие настройки, которые будут одинаковы для всех или большинства целевых таблиц ClickHouse (стратегия распределения нагрузки, необходимость использования staging-слоя, ограничения для батчей данных и так далее) можно указать на уровне объекта server, а частные настройки (имя конкретной таблицы) — на уровне foreign table.
- Обновлённый механизм распределения нагрузки по хостам. В новой версии коннектора список хостов ClickHouse, через которые будет производиться загрузка данных из ADB, указывается в опции hosts. Отдельная опция distribution_type отвечает за выбор стратегии распределения нагрузки между выбранными хостами. Поддерживаются два типа распределения: случайное и с использованием алгоритма round-robin.
- Гибкое управление кастомными настройками. Кастомные настройки подключения и выполнения запросов к ClickHouse теперь можно объявить в опции clickhouse_properties.
- Больший контроль над освобождением ресурсов. Foreign data wrapper поддерживает транзакции «из коробки», позволяя подписываться на хуки управления транзакциями. Благодаря этому новая версия коннектора обеспечивает больший контроль над ходом выполнения запросов и освобождением ресурсов.
- Упрощение синтаксиса запросов. Исключена необходимость использования функции txn для включения транзакционного режима (использования staging-слоя). В новой версии коннектора для передачи данных из ADB в ClickHouse достаточно выполнить обычный запрос INSERT к соответствующей foreign-таблице.
- Двусторонние коннекторы:
- Greengage/Greenplum <-> Kafka;
- Greengage/Greenplum <-> ClickHouse;
- Greengage/Greenplum <-> Spark;
- Greengage/Greenplum <-> Trino;
- ADB <-> ADB на основе FDW.
- ADB Control (мониторинг на уровне запросов).
- ADBM (управление бинарными резервными копиями).
- Реализация DR-кластера на основе физических резервных копий.
- Офлайн-установка.
- Управление развёртыванием и обновлением ПО.
- Расширение кластера.
- Мониторинг и alerting.
- Поддержка 24/7.
- 3-я линия поддержки.
- Обучение по продуктам.
- Вендорский консалтинг: пусконаладка, аудит и технадзор.
- Сертификация ФСТЭК по 4-му и 6-му УД.
- Управление развёртыванием и обновлением ПО.
- Автоматизированное расширение кластера.
- Мониторинг.
- Spark- и ADB-коннектор.
- Офлайн-установка.
- Возможность доработки и развития функционала продукта в соответствии с запросами заказчиков.
- Техническая поддержка.
- Обучение по продуктам.
- Проведение пилотных проектов.
- Вендорский консалтинг: пусконаладка, аудит и технадзор.
- ADQM Control — инструмент анализа и мониторинга пользовательских запросов и состояния кластеров ADQM, а также управление оповещениями.
- Сертификация ФСТЭК по 4 и 6 УД.
- Цель — быстрый PoC, учебная лаборатория, демо на конференции.
- Объём — 2–4 узла, с хранилищем до сотен ГБ и без круглосуточной нагрузки. Поддержка — через Telegram-каналы, «как получится». SLA, гарантий и подписанных обновлений нет. По условиям EULA использование Community Edition в продакшн-средах запрещено.
- Поддержка — Telegram-каналы, «как получится». SLA, гарантий и подписанных обновлений нет.
- Цель — реализация важных или критичных бизнес-задач, обеспечение SLA по доступу бизнес-пользователей к данным.
- Безопасность — Kerberos/LDAP, SAML-SSO, TLS, сертификаты ФСТЭК и т. д.
- Надёжность — встроенная репликация и DR-сценарии, автоматические бэкапы.
- Интеграции — готовые коннекторы, графический мониторинг, роллинг-апдейты через ADCM.
- Поддержка — юридические обязательства по SLA и работа 24/7.
- по архитектуре решения Greenplum/ADB (включая подключение и обзор системы);
- концепции простых и партиционированных таблиц и особенностям их реализации в Greenplum;
- работе с планами запросов и статистикой;
- особенностям многопользовательской работы в Greenplum (транзакции и блокировки);
- реализации хранимых функций.
- ETL- и ELT-процессы загрузки данных — классическая трансформация данных, наиболее эффективно показывают себя при in-database обработке.
- DWH-трансформации — любые другие виды трансформации, включая генерацию ключей и т. д.
- Большие JOIN — эффективное соединение больших таблиц, особенно в случаях объединения по заведомо заданному ключу распределения, эта СУБД хорошо объединяет большие таблицы как локально, так и распределённо.
- Ad-hoc deep dive — углублённый анализ по специализированным запросам, когда заранее неизвестно, какие данные понадобятся пользователю, но необходимо организовать к ним доступ и выделить ресурсы для их обработки.
- Аналитические функции на процедурных языках, в том числе и с помощью уже готовых библиотек алгоритмов MADLib.
- Wide data marts — работы с быстрыми витринами данных. Если витрины, созданные в Greenplum, выгружаются в ClickHouse, куда поступают однотипные предсказуемые запросы пользователей, запросы к быстрым витринам обрабатываются за миллисекунды.
- Wide fact tables — работы с широкими денормализованными таблицами фактов. Когда необходимо сохранить огромные массивы сырых данных, агрегировать их и дальше работать с агрегатами. Позволяет быстро делать сложные агрегации, запросы к таблицам обрабатываются за миллисекунды.
- AD-HOC — работы с несложными специализированными запросами к витринам данных, когда необходимо сохранить огромный массив сырых данных.
- Full-scan операции — работы с full-scan операциями при условии использовании фильтров, а также работы со структурированными логами и событиями.
-
С более детальной информацией можно ознакомиться по ссылке.
Community- vs enterprise-редакции: какую ставить сегодня и почему
Community-редакции Arenadata DB (ADB) и Arenadata QuickMarts (ADQM) остаются доступными всем желающим. Эти сборки основаны на актуальных ядрах Greengage и ClickHouse LTS, но упакованы и протестированы командой Arenadata: в них входят готовые пакеты для Linux, docker-образы и базовый набор утилит для установки и обновления кластера. Этого достаточно, чтобы за считаные часы развернуть учебный стенд, выполнить Proof-of-Concept или запустить небольшое внутреннее решение без SLA и сложных требований по безопасности.
Однако по мере роста объёмов и требований большинство команд переезжает на enterprise-дистрибутивы — у Arenadata это ADB и ADQM. Чем они отличаются от «комьюнити» — коротко по ключевым категориям.
Arenadata DB (ADB)
Arenadata QuickMarts (ADQM)
Community-версии для изучения
Когда брать — чтобы познакомиться с продуктом и технологией, проверить идею, изучить API или обкатать новую фичу.
Перед установкой просим ознакомиться с условиями и ограничениями использования ПО в Community Edition-редакции по ссылке.
Enterprise-версии — когда начинается продакшен
Когда брать — если простои измеряются деньгами/штрафами, есть регуляторика, нужна предсказуемая производительность и «одно окно» ответственности.
Рекомендация: для демо и обучения подойдут community-версии — ADB и ADQM можно развернуть за считаные минуты. Но если цель именно пилот, где важно протестировать функциональность Enterprise Edition (расширенные возможности по SLA, безопасности, отказоустойчивости и другим критичным функциям), начинать нужно сразу с неё. Это позволит пилотировать именно тот функционал, который будет востребован в продакшене, и избежать разрыва между PoC и промышленной эксплуатацией.
Как разобраться в Arenadata DB и Arenadata QuickMarts глубже
Центр обучения Arenadata предлагает актуальную линейку обучающих программ: краткие, практикоориентированные курсы с лабораторными работами, которые выполняются в удалённом стенде — достаточно браузера и VPN-доступа. Ниже — «выжимка» самых востребованных треков на текущий момент.
«Введение в ADB/Greenplum» — однодневный практический курс по работе с Greenplum/ADB. В его рамках участники получат теоретические знания и практический опыт:
«Arenadata DB для аналитиков» — 2-дневный курс для аналитиков и профильных специалистов, которые планируют научиться использовать ADB для задач обмена и анализа данных. Он даёт необходимые знания для эффективной и безопасной эксплуатации ADB в продуктовых средах, развёртывания схем и таблиц, написания процедур, оптимизации запросов, интеграции с другими системами. Освоение каждой практической темы подкрепляется лабораторной работой.
«Эксплуатация Arenadata DB» — 5-дневный курс для системных администраторов, архитекторов, разработчиков, аналитиков, использующих Arenadata DB. Он даёт необходимые знания для эффективной и безопасной эксплуатации ADB в продуктовых средах, загрузки, обработки и выгрузки данных, настроек безопасности и дополнительных расширений. Освоение каждой практической темы подкрепляется лабораторной работой.
«Arenadata DB для разработчиков» — интенсивный 5-дневный курс, который даёт необходимые знания для эффективной и безопасной эксплуатации ADB в продуктовых средах, развёртывания схем и таблиц, написания процедур, постройки витрин, загрузки, обработки и выгрузки данных, настройки безопасности и дополнительных расширений, позволяет решать проблемы с производительностью и другие часто возникающие ошибки.
«Arenadata QuickMarts для разработчиков» — предназначен для специалистов, организующих работу с данными в хранилищах на базе ADQM (ClickHouse). На курсе рассматриваются ключевые особенности СУБД и методы загрузки, формирования модели хранения и обработки данных с их учётом.
«Эксплуатация Arenadata QuickMarts» поможет специалистам детально разобраться в особенностях эксплуатации кластерной колоночной СУБД Arenadata QuickMarts (ClickHouse) и научиться успешно применять этот продукт в работе.
Оптимальные use-кейсы для Greenplum и ClickHouse
Суммировав все особенности обеих СУБД, мы выделили оптимальные, на наш взгляд, кейсы для каждого продукта.

Greenplum лучше всего справляется со следующими задачами:
А скоростной ClickHouse наиболее эффективен для:
Удачных запросов и быстрых ответов!
